General Programming Discussion
- pierre-couy.dev Mitosis in the Gray-Scott model : an introduction to writing shader-based chemical simulations
Use the parallel processing power of your GPU to simulate a simple chemical system that exhibits emergent behaviors
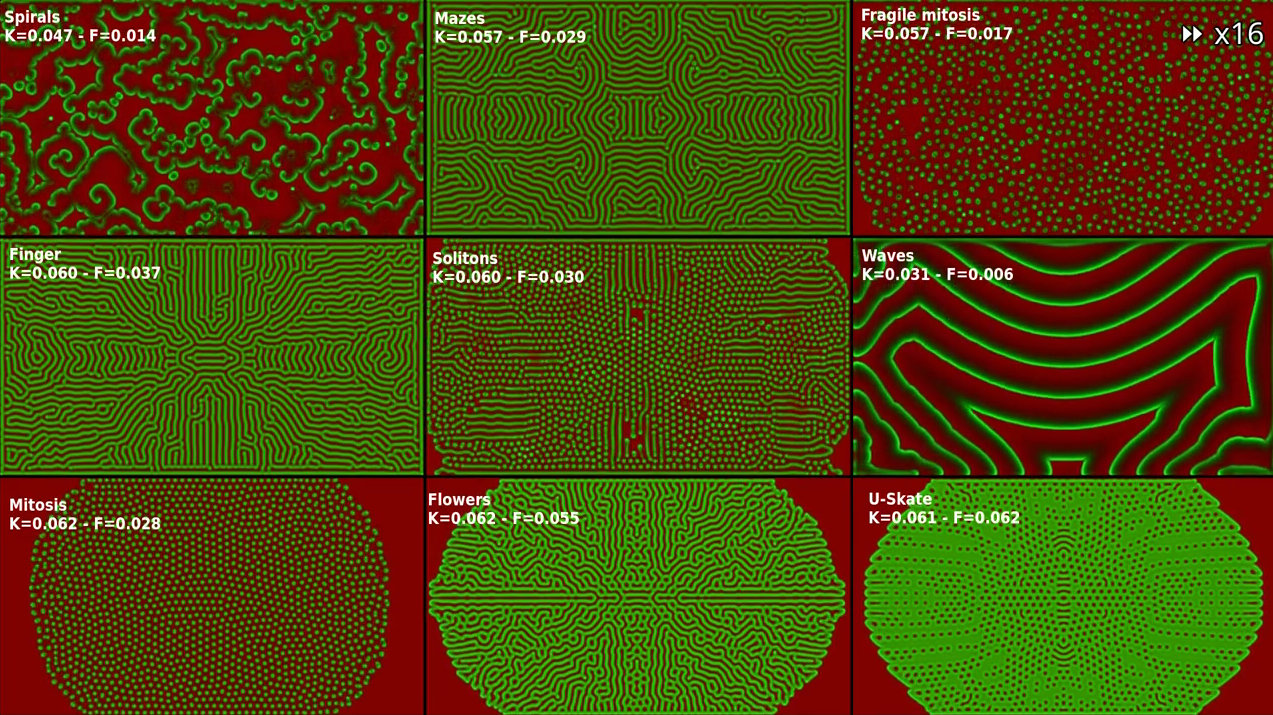
cross-posted from: https://lemmy.pierre-couy.fr/post/678825
Hi ! I've been working on this article for the past few days. It would mean a lot to me if you could provide some feedback.
It is about implementing a physico-chemical simulation as my first attempt to write a shader. The code is surprisingly simple and short (less than 100 lines). The "Prerequisite" and "Update rules" sections, however, may need some adjustments to make them clearer.
Thanks for reading
- • 100%www.qt.io Vector Graphics in Qt 6.8
An overview of the existing vector graphics solution in Qt 6.7 and prior, as well as the upcoming additions in Qt 6.8

Two-dimensional vector graphics has been quite prevalent in recent Qt release notes, and it is something we have plans to continue exploring in the releases to come. This blog takes a look at some of the options you have, as a Qt developer.
In Qt 6.6 we added support for a new renderer in Qt Quick Shapes, making it possible to render smooth, anti-aliased curves without enabling multisampling. The renderer was generalized to also support text rendering in Qt 6.7, and, in the same release, Qt SVG was expanded to support a bunch of new features.
And there is no end in sight yet: In Qt 6.8 we are bringing even more vector graphics goodies to the Qt APIs. In this blog, I will share some details on the different ways vector graphics can be used in Qt, as well as the benefits and drawbacks of each.
- github.com GitHub - guilhermeprokisch/see: A cute cat(1) for the terminal with advanced code viewing, Markdown rendering, 🌳 tree-sitter syntax highlighting, images view and more.
A cute cat(1) for the terminal with advanced code viewing, Markdown rendering, 🌳 tree-sitter syntax highlighting, images view and more. - guilhermeprokisch/see
I'm really bad at keeping my dependencies up-to-date manually, so dependabot was great for me. I don't use github anymore though, and I haven't really been able to find a good alternative.
I found Snyk, which seems to do that, but they only allow logging in with 3rd party providers which I'm not a big fan of.
Edit: seems like Snyk also only supports a few git hosts, and Codeberg isn't one of them.
- github.com GitHub - art-institute-of-chicago/aic-bash: A bash script to query our API for public domain artworks and render them as ASCII art
A bash script to query our API for public domain artworks and render them as ASCII art - art-institute-of-chicago/aic-bash

- • 100%github.com GitHub - free-news-api/news-api: Top Free News API Comparison
Top Free News API Comparison. Contribute to free-news-api/news-api development by creating an account on GitHub.
Taking accurate screenshots with Puppeteer has been a real pain, especially with pages that don’t fully load when the standard
waitUntil: loadfires. A real pain. Some sites, particularly SPAs built with Angular, React, or Vue, end up half-loaded, leaving me with screenshots where parts of the page are just blank. Peachy, just peachy.I've had the same issue with
waitUntil: domcontentloaded, but that one was kind of expected. The problem is that the page load event fires too early, and for pages relying on JavaScript to load images or other resources, this means the screenshot captures a half-baked page. Useless, obviously.After some digging accompanied by a certain type of language (the beep type), I did find a few workarounds. For example, you can use Puppeteer to wait for specific DOM elements to appear or disappear. Another approach is to wait for the network to be idle for a certain time. But what really helped was finding a custom function that waits for the DOM updates to settle (source). It’s the closest to a solution for getting fully loaded screenshots across different types of websites, at least from what I was able to find. Hope it will help anyone who struggles with this issue.
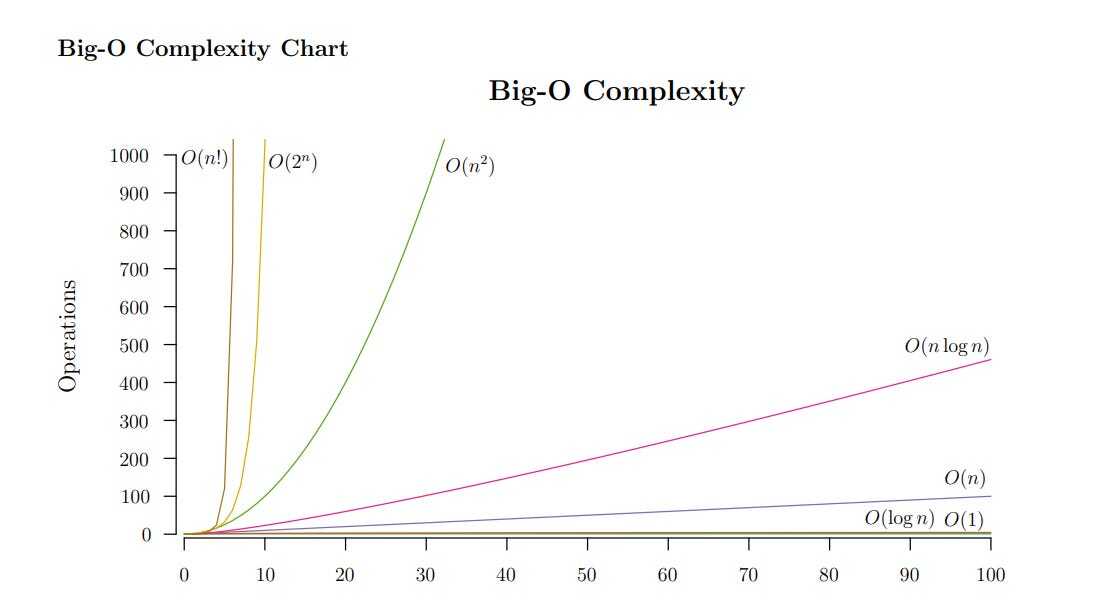
- • 100%photonlines.substack.com Visual Data Structures Cheat-Sheet
A visual overview of some of the key data-structures used in the real world.

- • 80%

I initially wrote this as a response to this joke post, but I think it deserves a separate post.
As a software engineer, I am deeply familiar with the concept of rubber duck debugging. It's fascinating how "just" (re-)phrasing a problem can open up path to a solution or shed light on own misconceptions or confusions. (As and aside, I find that among other things that have similar effect is writing commit messages, and also re-reading own code under a different "lighting": for instance, after I finish a branch and push it to GitLab, I will sometimes immediately go and review the code (or just the diff) in GitLab (as opposed to my terminal or editor) and sometimes realize new things.)
But another thing I've been realizing for some time is that these "a-ha" moments are always mixed feelings. Sure it's great I've been able to find the solution but it also feels like bit of a downer. I suspect that while crafting the question, I've been subconsciously also looking forward for the social interaction coming from asking that question. Suddenly belonging to a group of engineers having a crack at the problem.
The thing is: I don't get that with ChatGPT. I don't get that since there's was not going to be any social interaction to begin with.
With ChatGPT, I can do the rubber duck debugging thing without the sad part.
If no rubber duck debugging happens, and ChatGPT answers my question, then that's obvious, can move on.
If no rubber duck debugging happens, and ChatGPT fails to answer my question, then by the time at least I got some clarity about the problem which I can re-use to phrase my question with an actual community of peers, be it IRC channel, a Discord server or our team Slack channel.
---
So I'm wondering, do other people tend to use LLMs as these sort of interactive rubber ducks?
And as a bit of a stretch of this idea---could LLM be thought of as a tool to practice asking question, prior to actually asking real people?
---
PS: I should mention that I'm also not a native English speaker (which I guess is probably obvious by now by my writing) so part of my "learning asking question" is also learning it specifically in English.
I started writing this as an answer to someone on some discord, but it would not fit the channel topic, but I'd still love to see people's views on this.
So I'll quote the comment but just as a primer:
> The safest pattern to use is to not use any pattern at all and write the most straight forward code. Apply patterns only when the simplest code is actually causing real problems.
First and foremost: Many paths to hell are paved with design patterns applied willy-nilly. (A funny aside: OO community seems to be more active and organized in describing them (and often not warning strongly enough about dangers of inheritance, the true lord of the pattern rings), which leads to the lower-level, simpler patterns being underrepresented.)
But, the other extreme is not without issues, by far.
I've seen too many FastAPI endpoints talking to db like there's no tomorrow. That is definitely "straight forward" approach but the first problem is already there: it's pretty much untestable, and soon enough everyone is coupling to random DB columns (and making random assumptions about their content, usually based on "well let's see who writes what there" analysis) which makes it hard to change without playing a whack-a-bug.
And what? Our initial DB design was not future proof? Tough luck changing it now. So new endpoints will actually be trying to make up for the obsolete schema, using pandas everywhere to do what SQL or some storage layer (perhaps with some unit-of-work pattern) should be doing -- and further cementing in the obsolete design. Eventually it's close to impossible to know who writes/expects what, so now everyone better be defensive, adding even more cruft (and space for bugs).
My point is, I guess, that by the time when there are identifiable "real problems" to be solved by pattern, it's far too late.
Look, in general, postponing a decision to have more information can be a great strategy. But that depends on the quality of information you get by postponing. If that extra information is going to be just new features you added in the meantime, that is going to be heavily biased by the amount of defensive / making-up-for-bad-db junk that you forced yourself to keep adding. It's not necessarily going to be easier to see the right pattern.
So the tricky part is, which patterns are actually strong enough yet not necessarily obtrusive, so that you can start applying them early on? That's a million dollar question.
I don't think "straight forward" gets you towards answering that question. (Well, to be fair, I'm sure people have made $1M with "straight forward code", so that's that, but is that a good bet?)
(By the way, real world actually has a nice pattern specifically for getting out of that hole, and it's called "your competitor moving faster & being cheaper than you" so in a healthy market the problem should solve itself eventually...)
---
So what are your ideas? Do you have design patterns / disciplines that you tend to apply generally, with new projects?
I'm not looking for actual patterns (although it's fine to suggest your favorites, or link to resources), I'm mainly interested in what do people think about patterns in general, and how to apply them during the lifetime of the project.
- • 80%survey.stackoverflow.co 2024 Stack Overflow Developer Survey
In May 2024, over 65,000 developers responded to our annual survey about coding, the technologies and tools they use and want to learn, AI, and developer experience at work. Check out the results and see what's new for Stack Overflow users.
- www.haskellforall.com Software engineers are not (and should not be) technicians
Software engineers are not (and should not be) technicians I don’t actually think predictability is a goo...
- • 100%minimalmodeling.substack.com Sentinel-free schemas: a thought experiment
We systematically design a database schema that does not use NULLs and sentinel values. We look at the consequences of this design decisions and provide some guidance on designing the schemas that way.

- • 100%hackaday.com C++ Design Patterns For Low-Latency Applications
With performance optimizations seemingly having lost their relevance in an era of ever-increasing hardware performance, there are still many good reasons to spend some time optimizing code. In a re…
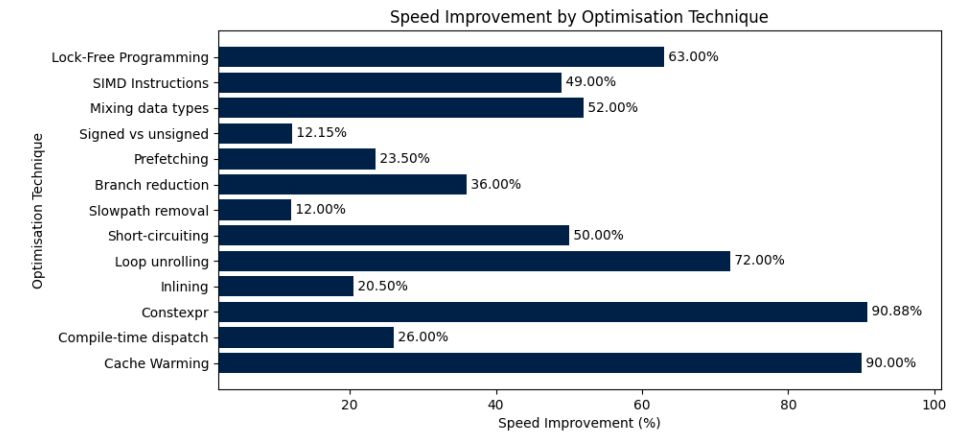
With performance optimizations seemingly having lost their relevance in an era of ever-increasing hardware performance, there are still many good reasons to spend some time optimizing code. In a recent preprint article by [Paul Bilokon] and [Burak Gunduz] of the Imperial College London the focus is specifically on low-latency patterns.
- mastodon.social Bahman M. (@bahmanm@mastodon.social)
Attached: 1 image My fellow software engineer, It's the year 2024. Please store your #Linux #desktop application configurations ONLY in `$XDG_CONFIG_HOME`. NOT in `$HOME` or other non-standard or obsolete places. May #FreeDesktop be your guide. https://www.freedesktop.org/wiki/Specifications/...

cross-posted from: https://lemmy.ml/post/17978313
> Shameless plug: I am the author.
Serious question. I know there are a lot of memes about microservices, both advocating and against it. And jokes from devs who go and turn monoliths into microservices and then back again. For my line of work it isn't all that relevant, but a discussion I heard today made me wonder.
There were two camps in this discussion. One side said microservices are the future, all big companies are moving towards it, the entire industry is moving towards it. In their view, if it wasn't Mach architecture, it wasn't valid software. In their world both software they made themselves and software bought or licensed (SaaS) externally should be all microservices, api first, cloud-native and headless. The other camp said it was foolish to think this is actually what's happening in the industry and depending on where you look microservices are actually abandoned instead of moving towards. By demanding all software to be like this you are limiting what there is on offer. Furthermore the total cost of operation would be higher and connecting everything together in a coherent way is a nightmare. Instead of gaining flexibility, one can actually lose flexibility because changing interfaces could be very hard or even impossible with software not fully under your own control. They argued a lot of the benefits are only slight or even nonexistent and not required in the current age of day.
They asked what I thought and I had to confess I didn't really have an answer for them. I don't know what the industry is doing and I think whether or not to use microservices is highly dependent on the situation. I don't know if there is a universal answer.
Do you guys have any good thoughts on this? Are microservices the future, or just a fad which needs to be forgotten ASAP.
It’s been over a year since Khronos started working on the Vulkan SC Ecosystem. Now that the component stack has reached a high level of maturity, it seemed appropriate to write an article about the secret sauce behind the Vulkan SC Ecosystem components that enabled us to leverage the industry-proven Vulkan Ecosystem components to provide corresponding developer tooling for the safety-critical variant of the API.
Vulkan SC was released by the Khronos Group in 2022 as the first of the new generation of explicit APIs to target safety-critical systems. The Vulkan SC 1.0 specification is based on the Vulkan 1.2 API and aims to enable safety-critical application developers access to and detailed control of the graphics and compute capabilities of modern GPUs. In order to accomplish that, Vulkan SC removes functionality from Vulkan 1.2 that is not applicable, not relevant, or otherwise not essential for safety-critical markets, and tweaks the APIs to achieve even more deterministic and robust behavior to meet safety certification standards.
The Vulkan SC Ecosystem components, such as the ICD Loader and Validation Layers, are not safety certified software components themselves, rather, they are developer tools intended to be used by application developers writing safety-critical applications using the Vulkan SC API. Building on the success of the corresponding ecosystem components available for the Vulkan API, the goal for the Vulkan SC Ecosystem is to leverage the tremendous engineering effort that went (and still goes) into those in order to create a comparably comprehensive suite of developer tools for the safety-critical variant of the API, amended with additional features specific to Vulkan SC. Reaching that goal, however, came with its own set of challenges…
Performance optimisation matters when you are trying to get your application working in a resource-constrained environment. This is typically the case in embedded but also in some desktop scenarious you may run short on resources so it’s not a matter without significance on desktop either.
What we mean by performance here is the ability to get the application running to fulfill its purpose, in practice typically meaning sufficient fps in the UI and meeting other nonfunctional requirements, such as startup time, memory consumption and CPU/GPU load.
There have been a number of discussions on Qt performance aspects and as we have been working on a number of related items we thought now could be a good time to provide a summary of all the activities and tools we have. You can optimise the performance of your application by utilising them and also use them in testing. We have been working on improving existing performance tools as well as adding new ones and providing guidelines, so let’s look at the latest additions. This post is starting a stream of blog posts to help you with performance optimisation and provide a view to our activities in this area.
https://github.com/phoboslab/q1k3
Hey, just uploading here at lemmy, so I can link an attachment to a Godot forum (new users to godot forum can't upload attachments).
But, if anyone here is a Godoteneer or programmer, I'd love to hear your ideas.
The attached demo is a simulation I did on Blender showing the type of interaction I mean. The green wire mesh represents a vertical plane that has the horizontal edge shaped by a bezier curve. The ball has a physics simulation on the up and down (z axis) with only horizontal movement on the (let's call it the c-axis). So, all linear movement on the c-axis is translated to a x and y position using the bezier plane.
My initial thoughts on how I might approach such a setup would be to create all nodes in 3d space except for the physics shapes. This might allow using the 2d physics shape but keep the 3d model meshes and lights. But the it would have to be a 2d RigidBody, and I'm not sure if I could translate a 2d position space to a 3d position space ... I think I need a broader understanding of the core code of Godot. In the past, I've been successful in a c++ Godot module, then later refactoring it to a GDExtension. But that was needed for a high performant line gesture engine. I haven't yet delved too much into the guts of Godot.
Any pointers? Or inspired thoughts?
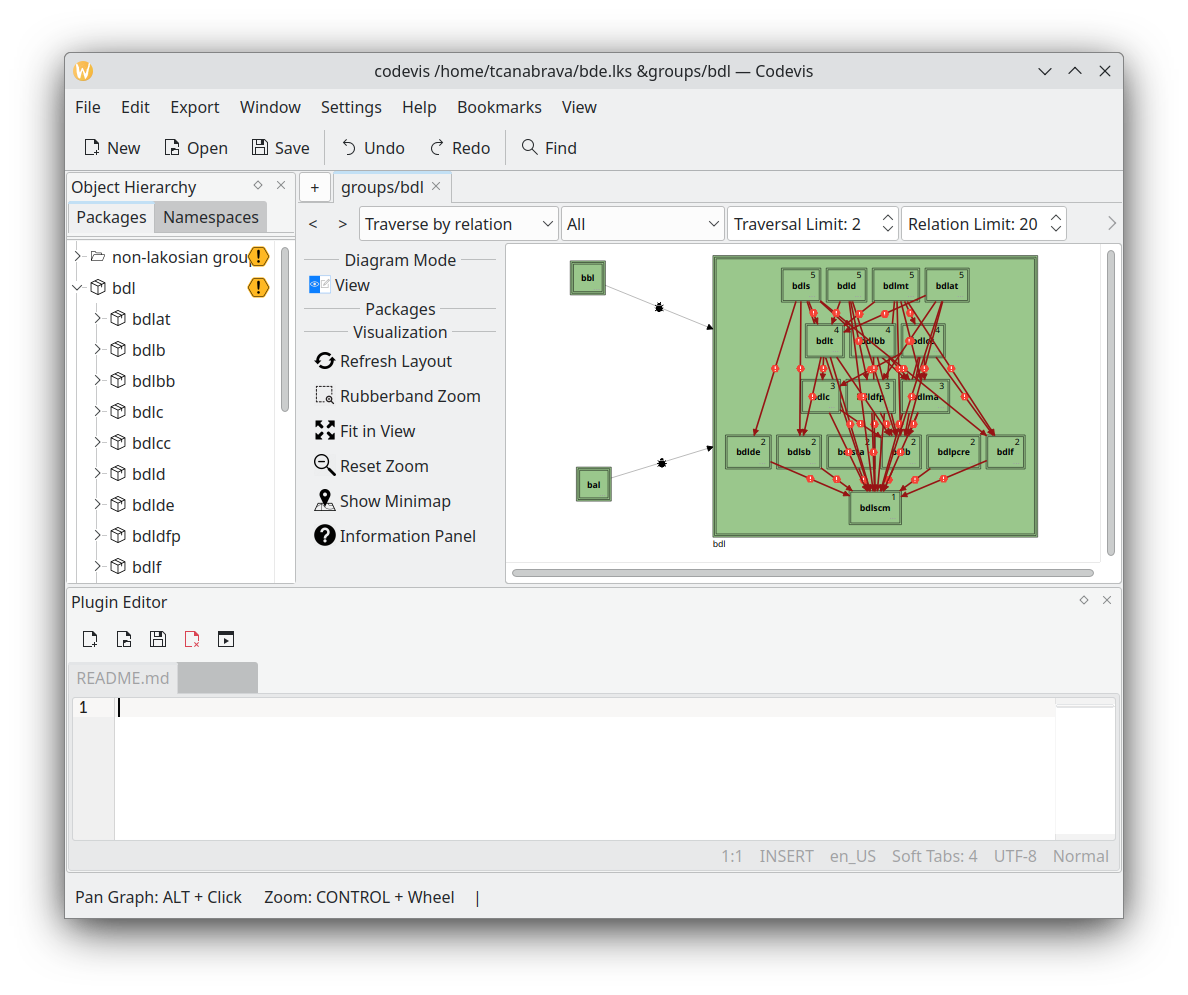
Codevis is a Large Scale software visualizer, focused on C++ codebases. it can help you identify issues and smells in your codebase. It also has an extensive plugin interface and some preliminary scripting support.
Features:
- Generate a Visualization from Pre-Existing code
- Generate architectural code from a visualization
- Plugin System that allows you to add missing features
- Architectural linters (not just code linters)
- DBus support
- visualstudiomagazine.com Open Source 'Eclipse Theia IDE' Exits Beta to Challenge Visual Studio Code -- Visual Studio Magazine
Some seven years in the making, the Eclipse Foundation's Theia IDE project is now generally available, emerging from beta to challenge Microsoft's similar Visual Studio Code editor, with which it shares much tech.

- • 33%quic.video Never* use Datagrams - Media over QUIC
Media over QUIC is a new live media protocol in development by the IETF.
I'm in the course of pursuing a change in my career towards software engineering/architecture. So far I've been brought mostly to C#/.NET and Java, though Java attracts me more, even considering that it might be a "dying" language. Still, Scala and Clojure are there, so I thought that they might give a pump at least to JVMs. In your opinion, should I invest in pursuing certifications/jobs in this field, or sticking to C#/.NET is a better path?
- www.theregister.com 268% higher failure rates for Agile software projects
In praise of knowing the requirements before you start cranking out code

- • 80%blog.partykit.io Using Vectorize to build an unreasonably good search engine in 160 lines of code
PartyKit now includes a vector database and access to an embedding model. Here’s a guide on how to use them to build a search engine.

- www.kdab.com KDGpu 0.5.0 is here!
Our Vulkan wrapper KDGpu has evolving! Explore it's new features like OpenXR integration and wider device support.

Since we first announced it last year, our Vulkan wrapper KDGpu has been busy evolving to meet customer needs and our own. Our last post announced the public release of v0.1.0, and version 0.5.0 is available today. It’s never been easier to interact with modern graphics technologies, enabling you to focus on the big picture instead of hassling with the intricacies and nuances of Vulkan.
- • 81%theconversation.com Why are algorithms called algorithms? A brief history of the Persian polymath you’ve likely never heard of
Our modern lives are influenced by algorithms at every step. We can trace this influence back more than 1,200 years ago – to a Muslim mathematician.

I just want to build requests and read the responses, why the hell does everyone suddenly want me to make an account?
- github.com GitHub - youtube/cobalt: Cobalt is a lightweight HTML5 application container
Cobalt is a lightweight HTML5 application container - youtube/cobalt
