
Singularity | Artificial Intelligence (ai), Technology & Futurology
Some days ago I made a rule 9 which goes:
>(Rule implemented 30.06.2023) Don’t make posts with link/s to tweets as their main focus. Melon decided that the content on the platform is going to be locked behind login requirement and I’m not going to force everyone to make a twitter account just so they can see some news.
From what I see you can view tweets now but you can't see comments for them etc.
Should I revert the ban or should I do the same like I did with reddit in rule 4?:
>No posts linking to reddit posts.
Personally I want to keep the ban because the platform doesn't deserve traffic and is very unstable right now where we can't trust that they won't block us from viewing the tweets again. What do you think? I want to hear your opinions on the topic. I will do my final decision tomorrow.
If you are lurker please help us grow the community by commenting and posting interesting on topic quality info/discussions so we can attract more people and make this community more interesting to spend time on. ✌️
Previous milestone: https://lemmy.fmhy.ml/post/578477
- https:// arxiv.org /abs/2306.15195
>In human conversations, individuals can indicate relevant regions within a scene while addressing others. In turn, the other person can then respond by referring to specific regions if necessary. This natural referential ability in dialogue remains absent in current Multimodal Large Language Models (MLLMs). To fill this gap, this paper proposes an MLLM called Shikra, which can handle spatial coordinate inputs and outputs in natural language. Its architecture consists of a vision encoder, an alignment layer, and a LLM. It is designed to be straightforward and simple, without the need for extra vocabularies, position encoder, pre-/post-detection modules, or external plug-in models. All inputs and outputs are in natural language form. Referential dialogue is a superset of various vision-language (VL) tasks. Shikra can naturally handle location-related tasks like REC and PointQA, as well as conventional VL tasks such as Image Captioning and VQA. Experimental results showcase Shikra's promising performance. Furthermore, it enables numerous exciting applications, like providing mentioned objects' coordinates in chains of thoughts and comparing user-pointed regions similarities. Our code, model and dataset are accessed at this https URL.
- https:// fortune.com /2023/07/07/andy-jassy-dismisses-microsoft-google-ai-hype-cycle-amazon-starting-substance-cycle/
>Amazon CEO Andy Jassy called generative A.I. “one of the biggest technical transformations of our lifetimes” in an interview with CNBC on Thursday. He also called many of today’s A.I. chatbots and other generative A.I. tools part of the “hype cycle,” declaring that Amazon was focused on the “substance cycle.” > >Amazon’s bona fides in the space are well established, having been a player in artificial intelligence and machine learning long before the ChatGPTs and Bards of the world were publicly released. Former Fortune editor Brian Dumaine wrote a book in 2020 about how Amazon founder Jeff Bezos realized early on that imbuing machine learning into every facet of the company would allow it to gather data to constantly improve itself. > >Much as it did with Amazon Web Services, which practically birthed the cloud computing industry that now powers the internet’s biggest companies, including its competitors, Amazon’s A.I. strategy is focused on cementing its position as a major player across the entirety of the A.I. supply chain. > >“Every single business unit inside of Amazon is working intensely and very broadly on generative A.I.,” Jassy says. > >Jassy shed some light on Amazon’s A.I. game plan, outlining three macro layers: the computing capabilities, the underlying models, and what Jassy refers to as the “application layer,” for example, ChatGPT or Bard.
- https:// arxiv.org /abs/2306.14896
>For 3D object manipulation, methods that build an explicit 3D representation perform better than those relying only on camera images. But using explicit 3D representations like voxels comes at large computing cost, adversely affecting scalability. In this work, we propose RVT, a multi-view transformer for 3D manipulation that is both scalable and accurate. Some key features of RVT are an attention mechanism to aggregate information across views and re-rendering of the camera input from virtual views around the robot workspace. In simulations, we find that a single RVT model works well across 18 RLBench tasks with 249 task variations, achieving 26% higher relative success than the existing state-of-the-art method (PerAct). It also trains 36X faster than PerAct for achieving the same performance and achieves 2.3X the inference speed of PerAct. Further, RVT can perform a variety of manipulation tasks in the real world with just a few (∼10) demonstrations per task. Visual results, code, and trained model are provided at this https URL.
- bioinformant.com How Topical Application of Stem Cell Serum Can Reverse COVID-Induced Hair Loss | BioInformant
What is Covid-related hair loss? Covid-19 is said to cause long-term side effects in up to 67% of patients, and these health consequences can include chronic fatigue, loss of taste and smell and brain fog. Increasingly common too is Covid-related hair loss. Known as telogen effluvium, this phenomeno...

>Covid-19 is said to cause long-term side effects in up to 67% of patients, and these health consequences can include chronic fatigue, loss of taste and smell and brain fog. Increasingly common too is Covid-related hair loss. Known as telogen effluvium, this phenomenon manifests as clumps of hair falling out after brushing or washing your hair. > >It’s normal to shed hair daily – we lose about 100-150 hairs each day as hair drops from follicles to make way for new hair growth. This growth cycle occurs because 90% of the hair on our heads is in a growth phase (called anagen), while the remaining 10% is in a resting phase (called telogen). Anagen lasts for about three years before transitioning into the shorter telogen phase, following which hair is shed. > >A stressful event like childbirth, certain medications, intense psychological stress and Covid-19 can trigger our bodies to shift a greater-than-normal proportion of growing anagen hairs into a resting telogen state, according to the University of Utah. > >“Covid-related hair loss can affect up to 33% of symptomatic patients and 10% of asymptomatic patients,” says a plastic surgeon who deals with hair loss patients. “And this kind of hair loss seems to be different from that induced by stress or disease as cytokines (substances secreted by the body’s immune system) appear to cause direct damage to hair follicles,” she adds. > >Covid-induced hair loss has also been reported to start earlier after the stressful event – in two months instead of the usual three.
- https:// www.oejournal.org /article/doi/10.29026/oea.2023.220113
>Abstract: > >Since the first laser was invented, the pursuit of high-energy lasers (HELs) has always been enthusiastic. The first revolution of HELs was pushed by the fusion of laser and aerospace in the 1960s, with the chemical rocket engines giving fresh impetus to the birth of gas flow and chemical lasers, which finally turned megawatt lasers from dream into reality. Nowadays, the development of HELs has entered the age of electricity as well as the rocket engines. The properties of current electric rocket engines are highly consistent with HELs’ goals, including electrical driving, effective heat dissipation, little medium consumption and extremely light weight and size, which inspired a second fusion of laser and aerospace and motivated the exploration for potential HELs. As an exploratory attempt, a new configuration of diode pumped metastable rare gas laser was demonstrated, with the gain generator resembling an electric rocket-engine for improved power scaling ability.
- https:// arxiv.org /abs/2307.03170
Original title: Focused Transformer: Contrastive Training for Context Scaling
>Large language models have an exceptional capability to incorporate new information in a contextual manner. However, the full potential of such an approach is often restrained due to a limitation in the effective context length. One solution to this issue is to endow an attention layer with access to an external memory, which comprises of (key, value) pairs. Yet, as the number of documents increases, the proportion of relevant keys to irrelevant ones decreases, leading the model to focus more on the irrelevant keys. We identify a significant challenge, dubbed the distraction issue, where keys linked to different semantic values might overlap, making them hard to distinguish. To tackle this problem, we introduce the Focused Transformer (FoT), a technique that employs a training process inspired by contrastive learning. This novel approach enhances the structure of the (key, value) space, enabling an extension of the context length. Our method allows for fine-tuning pre-existing, large-scale models to lengthen their effective context. This is demonstrated by our fine-tuning of 3B and 7B OpenLLaMA checkpoints. The resulting models, which we name LongLLaMA, exhibit advancements in tasks requiring a long context. We further illustrate that our LongLLaMA models adeptly manage a 256k context length for passkey retrieval.
- www.theverge.com ChatGPT gets the headlines, but scientific research like AlphaFold is also the future of AI, says Google DeepMind CEO Demis Hassabis
The buzz around AI has moved from science research to chatbots, but Google DeepMind’s CEO says it’s all relevant to progress.

- shadowprotocol.net The Promise and Peril of AI-Generated TV: A Future Broken or Remade? - Shadow Protocol
The digital plane we traverse is volatile and ever-changing, evolving at a pace that leaves the old world gasping for breath. One of the newest entrants in the tech theatre is the use of AI in content creation, specifically television. Fable, a San Fransisco-based start-up, is pioneering this bold f...

The digital plane we traverse is volatile and ever-changing, evolving at a pace that leaves the old world gasping for breath. One of the newest entrants in the tech theatre is the use of AI in content creation, specifically television. Fable, a San Fransisco-based start-up, is pioneering this bold frontier. Their brainchild, aptly named the Showrunner AI technology, or ‘SHOW-1’, aims to generate TV shows with viewers as starring roles.
I just copy/pasted what's in the link so formatting may be broken:
>GPT-4's details are leaked. > >It is over. > >Everything is here: twitter.com/i/web/status/1… Parameters count: > >GPT-4 is more than 10x the size of GPT-3. We believe it has a total of ~1.8 trillion parameters across 120 layers. Mixture Of Experts - Confirmed. > >OpenAI was able to keep costs reasonable by utilizing a mixture of experts (MoE) model. They utilizes 16 experts within their model, each is about ~111B parameters for MLP. 2 of these experts are routed to per forward pass. MoE Routing: > >While the literature talks a lot about advanced routing algorithms for choosing which experts to route each token to, OpenAI’s is allegedly quite simple, for the current GPT-4 model. > >There roughly ~55B shared parameters for attention. Inference: > >Each forward pass inference (generation of 1 token) only utilizes ~280B parameters and ~560 TFLOPs. This contrasts with the ~1.8 trillion parameters and ~3,700 TFLOP that would be required per forward pass of a purely dense model. Dataset: > >GPT-4 is trained on ~13T tokens. > >These are not unique tokens, they count the epochs as more tokens as well. > >Epoch number: 2 epochs for text-based data and 4 for code-based data. > >There is millions of rows of instruction fine-tuning data from ScaleAI & internally. GPT-4 32K > >There was an 8k context length (seqlen) for the pre-training phase. The 32k seqlen version of GPT-4 is based on fine-tuning of the 8k after the pre-training. Batch Size: > >The batch size was gradually ramped up over a number of days on the cluster, but by the end, OpenAI was using a batch size of 60 million! This, of course, is “only” a batch size of 7.5 million tokens per expert due to not every expert seeing all tokens. For the real batch size: Divide this number by the seq len to get the real batch size. just stop with this misleading numbers already. Parallelism Strategies > >To parallelize across all their A100s GPUs They utilized 8-way tensor parallelism as that is the limit for NVLink. > >Beyond that, they are using 15-way pipeline parallelism. > >(likely used ZeRo Stage 1. It is possible they used block-level FSDP) Training Cost > >OpenAI’s training FLOPS for GPT-4 is ~2.15e25, on ~25,000 A100s for 90 to 100 days at about 32% to 36% MFU. > >Part of this extremely low utilization is due to an absurd number of failures requiring checkpoints that needed to be restarted from. If their cost in the cloud was about $1 per A100 hour, the training costs for this run alone would be about $63 million. > >(Today, the pre-training could be done with ~8,192 H100 in ~55 days for $21.5 million at $2 per H100 hour.) Mixture of Expert Tradeoffs > >There are multiple MoE tradeoffs taken: For example, MoE is incredibly difficult to deal with on inference because not every part of the model is utilized on every token generation. This means parts may sit dormant when other parts are being used. When serving users, this really hurts utilization rates. > >Researchers have shown that using 64 to 128 experts achieves better loss than 16 experts, but that’s purely research. There are multiple reasons to go with fewer experts. One reason for OpenAI choosing 16 experts is because more experts are difficult to generalize at many tasks. More experts can also be more difficult to achieve convergence with. With such a large training run, OpenAI instead chose to be more conservative on the number of experts. GPT-4 Inference Cost > >GPT-4 costs 3x that of the 175B parameter Davinchi. This is largely due to the larger clusters required for GPT-4 and much lower utilization achieved. AN estimate of it's costs is $0.0049 cents per 1k tokens for 128 A100s to inference GPT-4 8k seqlen and $0.0021 cents per 1k tokens for 128 H100’s to inference GPT-4 8k seqlen. It should be noted, we assume decent high utilization, and keeping batch sizes high. Multi-Query Attention > >OpenAI are using MQA just like everybody else. Because of that only 1 head is needed and memory capacity can be significantly reduced for the KV cache. Even then, the 32k seqlen GPT-4 definitely cannot run on 40GB A100s, and the 8k is capped on max bsz. Continuous batching > >OpenAI implements both variable batch sizes and continuous batching. This is so as to allow some level of maximum latency as well optimizing the inference costs. Vision Multi-Modal > >It is a separate vision encoder from the text encoder, with cross-attention. The architecture is similar to Flamingo. This adds more parameters on top of the 1.8T of GPT-4. It is fine-tuned with another ~2 trillion tokens, after the text only pre-training. On the vision model, OpenAI wanted to train it from scratch, but it wasn’t mature enough, so they wanted to derisk it by starting with text. One of the primary purposes of this vision capability is for autonomous agents able to read web pages and transcribe what’s in images and video. Some of the data they train on is joint data (rendered LaTeX/text), screen shots of web page, youtube videos: sampling frames, and run Whisper around it to get transcript. > >[Dont want to say "I told you so" but..] Speculative Decoding > >OpenAI might be using speculative decoding on GPT-4's inference. (not sure 100%) > >The idea is to use a smaller faster model to decode several tokens in advance, and then feeds them into a large oracle model as a single batch. If the small model was right about its predictions – the larger model agrees and we can decode several tokens in a single batch. But if the larger model rejects the tokens predicted by the draft model then the rest of the batch is discarded. And we continue with the larger model. The conspiracy theory that the new GPT-4 quality had been deteriorated might be simply because they are letting the oracle model accept lower probability sequences from the speculative decoding model. Inference Architecture > >The inference runs on a cluster of 128 GPUs. > >There are multiple of these clusters in multiple datacenters in different locations. > >It is done in 8-way tensor parallelism and 16-way pipeline parallelism. > >Each node of 8 GPUs has only ~130B parameters, or… twitter.com/i/web/status/1… The model has 120, so it fits in 15 different nodes. [Possibly the there are less layers on the first node since it needs to also compute the embeddings] According to these numbers: OpenAI should have trained on 2x the tokens if they were trying to go by chinchilla's optimal. > >[let alone surpass it like we do] > >This goes to show that they are struggling to get high quality data. Why no FSDP? > >A possible reason for this could be that some of the hardware infra they secured is of an older generation. > >This is pretty common at local compute clusters as the organisation usually upgrade the infra in several "waves" to avoid a complete pause of operation.… twitter.com/i/web/status/1… Dataset Mixture > >They trained on 13T tokens. CommonCrawl & RefinedWeb are both 5T. > >Remove the duplication of tokens from multiple epochs and we get to a much reasonable number of "unaccounted for" tokens: The "secret" data. Which by this point we already get rumors that parts of it came from twitter, reddit & youtube. > >[Rumors that start to become lawsuits] > >Some speculations are: >- LibGen (4M+ books) >- Sci-Hub (80M+ papers) >- All of GitHub > >My own opinion: > >The missing dataset it a custom dataset of college textbooks collected by hand for as much courses as possible. > >This is very easy to convert to txt file and than with self-instruct into instruction form. This creates the "illusion" that GPT-4 "is smart" no matter who use it. > >Computer scientist? sure! it can help you with your questions about P!=NP Philosophy major? It can totally talk to you about epistemology. > >Don't you see? It was trained on the textbooks. It is so obvious. There are also papers that try to extract by force memorized parts of books from GPT-4 to understand what it trained on. > >There are some books it knows so well that it had seen them for sure. > >Moreover, If i remember correctly: It even know the unique ids of project Euler exes.
- aisupremacy.substack.com A.I. Health scans are going to become the Norm
🩺 The A.I. of preventative healthcare is going to get pretty crazy.

- general-pattern-machines.github.io Large Language Models as General Pattern Machines
Large Language Models as General Pattern Machines
>Abstract: > >We observe that pre-trained large language models (LLMs) are capable of autoregressively completing complex token sequences -- from arbitrary ones procedurally generated by probabilistic context-free grammars (PCFG), to more rich spatial patterns found in the Abstract Reasoning Corpus (ARC), a general AI benchmark, prompted in the style of ASCII art. Surprisingly, pattern completion proficiency can be partially retained even when the sequences are expressed using tokens randomly sampled from the vocabulary. These results suggest that without any additional training, LLMs can serve as general sequence modelers, driven by in-context learning. In this work, we investigate how these zero-shot capabilities may be applied to problems in robotics -- from extrapolating sequences of numbers that represent states over time to complete simple motions, to least-to-most prompting of reward-conditioned trajectories that can discover and represent closed-loop policies (e.g., a stabilizing controller for CartPole). While difficult to deploy today for real systems due to latency, context size limitations, and compute costs, the approach of using LLMs to drive low-level control may provide an exciting glimpse into how the patterns among words could be transferred to actions.
- www.maginative.com China's Baichuan Intelligent Technology Unveils Open-Source 13B Parameter Large Language Model
The model has set a new benchmark, outstripping Meta's LLaMa-13B by a substantial 40% in training data volume.

- www.anthropic.com Claude 2
We are pleased to announce Claude 2, our newest model, which can be accessed via API as well as a new public-facing beta website at claude.ai.

cross-posted from: https://lemmy.world/post/1750098
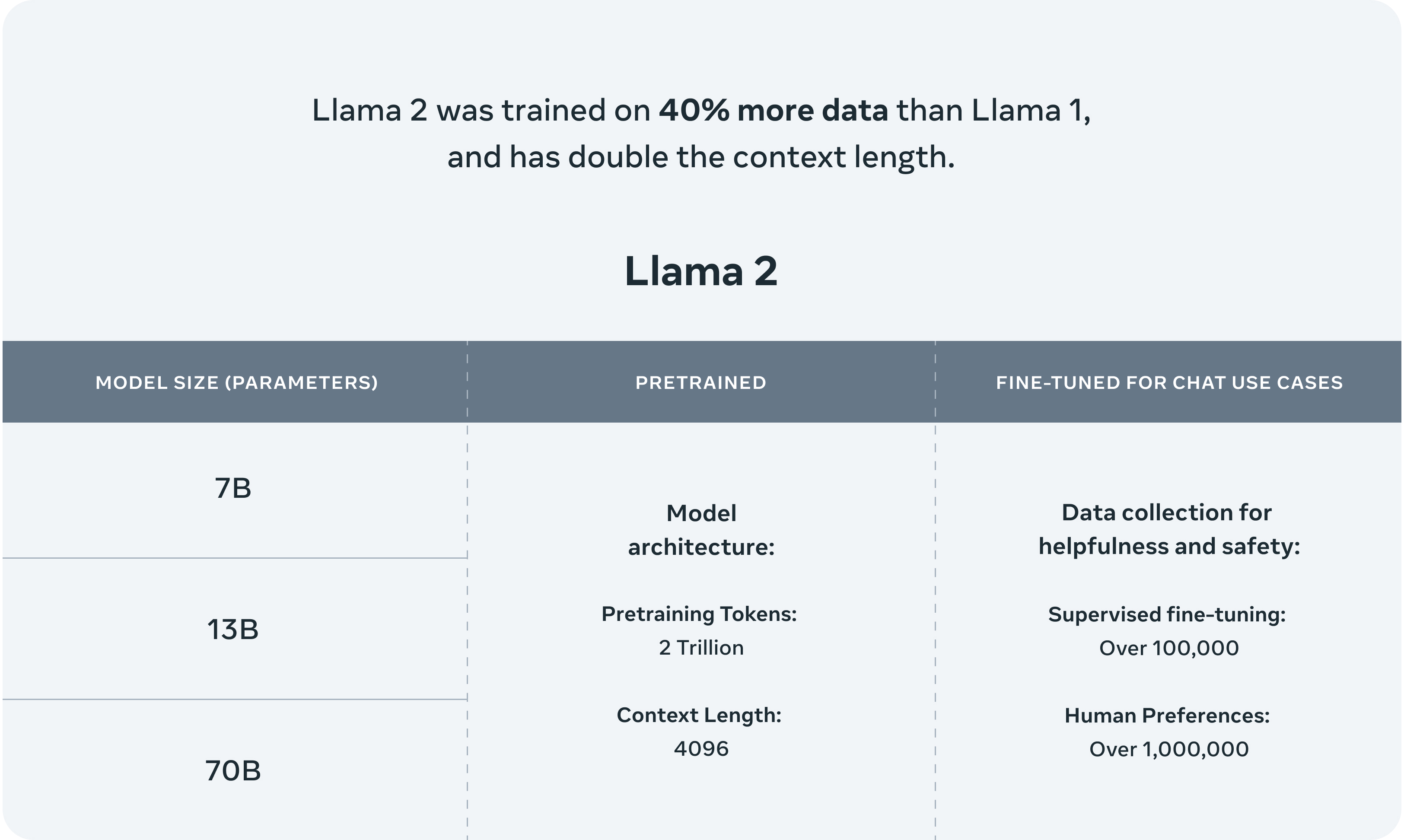
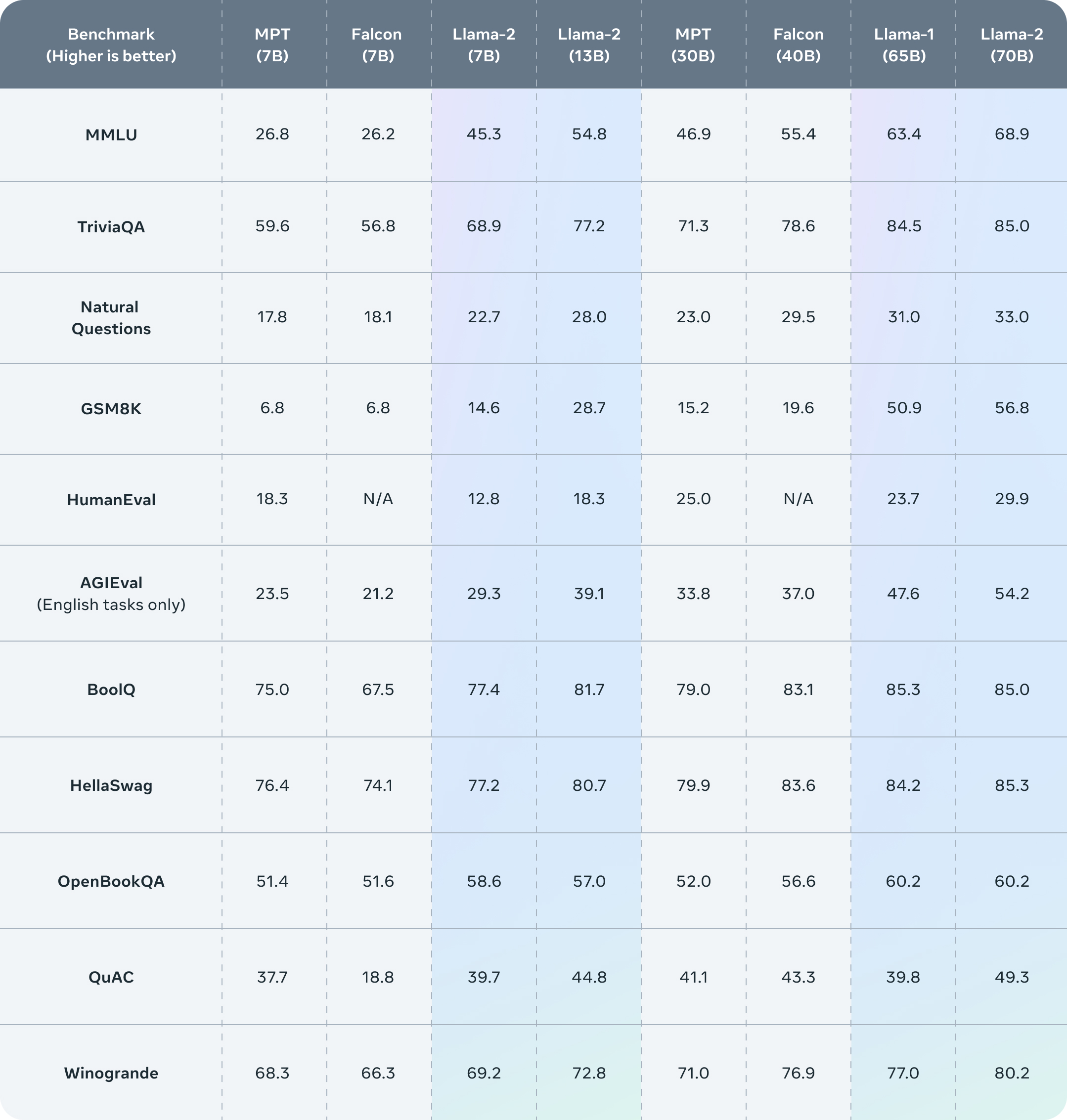
> ## Introducing Llama 2 - Meta's Next Generation Free Open-Source Artificially Intelligent Large Language Model > > !Llama 2 > > It's incredible it's already here! This is great news for everyone in free open-source artificial intelligence. > > Llama 2 unleashes Meta's (previously) closed model (Llama) to become free open-source AI, accelerating access and development for large language models (LLMs). > > This marks a significant step in machine learning and deep learning technologies. With this move, a widely supported LLM can become a viable choice for businesses, developers, and entrepreneurs to innovate our future using a model that the community has been eagerly awaiting since its initial leak earlier this year. > > - Meta Announcement > - Meta Overview > - Github > - Paper > > Here are some highlights from the official Meta AI announcement: > > ## Llama 2 > > >In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. > > > >Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closedsource models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs. > > >Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations. > > ## Inside the Model > > - Technical details > > ### With each model download you'll receive: > > - Model code > - Model Weights > - README (User Guide) > - Responsible Use Guide > - License > - Acceptable Use Policy > - Model Card > > ## Benchmarks > > >Llama 2 outperforms other open source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests. It was pretrained on publicly available online data sources. The fine-tuned model, Llama-2-chat, leverages publicly available instruction datasets and over 1 million human annotations. > > ! > > ## RLHF & Training > > >Llama-2-chat uses reinforcement learning from human feedback to ensure safety and helpfulness. Training Llama-2-chat: Llama 2 is pretrained using publicly available online data. An initial version of Llama-2-chat is then created through the use of supervised fine-tuning. Next, Llama-2-chat is iteratively refined using Reinforcement Learning from Human Feedback (RLHF), which includes rejection sampling and proximal policy optimization (PPO). > > ! > > ## The License > > >Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements. > > >Partnerships > > >We have a broad range of supporters around the world who believe in our open approach to today’s AI — companies that have given early feedback and are excited to build with Llama 2, cloud providers that will include the model as part of their offering to customers, researchers committed to doing research with the model, and people across tech, academia, and policy who see the benefits of Llama and an open platform as we do. > > ## The/CUT > > With the release of Llama 2, Meta has opened up new possibilities for the development and application of large language models. This free open-source AI not only accelerates access but also allows for greater innovation in the field. > > Take Three: > > - Video Game Analogy: Just like getting a powerful, rare (or previously banned) item drop in a game, Llama 2's release gives developers a powerful tool they can use and customize for their unique quests in the world of AI. > - Cooking Analogy: Imagine if a world-class chef decided to share their secret recipe with everyone. That's Llama 2, a secret recipe now open for all to use, adapt, and improve upon in the kitchen of AI development. > - Construction Analogy: Llama 2 is like a top-grade construction tool now available to all builders. It opens up new possibilities for constructing advanced AI structures that were previously hard to achieve. > > ## Links > > Here are the key resources discussed in this post: > > - Meta Announcement > - Meta Overview > - Github > - Paper > - Technical details > > Want to get started with free open-source artificial intelligence, but don't know where to begin? > > Try starting here: > > - FOSAI Welcome Message > - FOSAI Crash Course > - FOSAI Nexus Resource Hub > > If you found anything else about this post interesting - consider subscribing to !fosai@lemmy.world where I do my best to keep you in the know about the most important updates in free open-source artificial intelligence. > > This particular announcement is exciting to me because it may popularize open-source principles and practices for other enterprises and corporations to follow. > > We should see some interesting models emerge out of Llama 2. I for one am looking forward to seeing where this will take us next. Get ready for another wave of innovation! This one is going to be big.
- www.maginative.com Google DeepMind, OpenAI, and Leading Academics Propose International Institutions for Global AI Governance
A new white paper explores models and functions of international institutions that could help manage opportunities and mitigate risks of advanced AI

- https:// singularityhub.com /2023/07/11/ai-agents-with-multiple-selves-can-rapidly-adapt-to-a-changing-world/
> ### Significance > >Adaptive agents must continually satisfy a range of distinct and possibly conflicting needs. In most models of learning, a monolithic agent tries to maximize one value that measures how well it balances its needs. However, this task is difficult when the world is changing and needs are many. Here, we considered an agent as a collection of modules, each dedicated to a particular need and competing for control of action. Compared to the standard monolithic approach, modular agents were much better at maintaining homeostasis of a set of internal variables in simulated environments, both static and changing. These results suggest that having “multiple selves” may represent an evolved solution to the universal problem of balancing multiple needs in changing environments. > >### Abstract > >Satisfying a variety of conflicting needs in a changing environment is a fundamental challenge for any adaptive agent. Here, we show that designing an agent in a modular fashion as a collection of subagents, each dedicated to a separate need, powerfully enhanced the agent’s capacity to satisfy its overall needs. We used the formalism of deep reinforcement learning to investigate a biologically relevant multiobjective task: continually maintaining homeostasis of a set of physiologic variables. We then conducted simulations in a variety of environments and compared how modular agents performed relative to standard monolithic agents (i.e., agents that aimed to satisfy all needs in an integrated manner using a single aggregate measure of success). Simulations revealed that modular agents a) exhibited a form of exploration that was intrinsic and emergent rather than extrinsically imposed; b) were robust to changes in nonstationary environments, and c) scaled gracefully in their ability to maintain homeostasis as the number of conflicting objectives increased. Supporting analysis suggested that the robustness to changing environments and increasing numbers of needs were due to intrinsic exploration and efficiency of representation afforded by the modular architecture. These results suggest that the normative principles by which agents have adapted to complex changing environments may also explain why humans have long been described as consisting of “multiple selves.”
PIKA LABS site: https://www.pika.art/demo
- www.wired.com A Hair Loss Study Raises New Questions About Aging Cells
A protein secreted by seemingly dormant cells in skin moles causes hair to grow again. That’s a big—and potentially useful—surprise.

>A protein secreted by seemingly dormant cells in skin moles causes hair to grow again. That’s a big—and potentially useful—surprise.
Looking for a self hosting solution or some free alternatives for either chatgpt 4 or ideally sudowrite.
The latter does most of what I want it to do, but the free trial is super limiting and the paid tier is asking too much for not much of a word bump.
The former is only available with a sub but it requires way too much fiddling considering I'd be paying 20$ a month to do what I want but is an option. Sadly, I need gpt4 if I go that route and can't cruise on 3.5 for free.
I'm writing a novel and while I don't care about AI doing the actual writing for me, I do want something to help me organize my ideas or even brainstorm. gpt 3.5 just doesn't have the token bandwidth to do that. Sudowrite does an excellent job with it, but the pricing is stupid at 10$ for 30k words. I went through the 4k free trial just trying to figure out how it works.
I know there's a slew of self hosting chatbots but I haven't seen anyone use them for writing and searching huggingface is a pita.
Google bard could be an option but haven't found a way to jailbreak it and Claude is not available in my country.
Any ideas?
- www.maginative.com China Issues Rules for Generative AI, Mandating Adherence to 'Socialist Values'
With the new rules, China seeks to strike a balance between advancing their AI capabilities while maintaining rigid ideological control.

Bing (multimodal) image input is free!
- • 86%
The Disappearing Computer: An Exclusive Preview of Humane’s Screenless Tech | Imran Chaudhri | TED
Apple designer and Humane cofounder Imran Chaudhri envisions a future where AI enables using a phone without a screen
https://www.businessinsider.com/ai-chatbot-ceo-laid-off-staff-human-support-2023-7?IR=T
>Abstract: > >Large language models (LLMs) have demonstrated impressive results in developing generalist planning agents for diverse tasks. However, grounding these plans in expansive, multi-floor, and multi-room environments presents a significant challenge for robotics. We introduce SayPlan, a scalable approach to LLM-based, large-scale task planning for robotics using 3D scene graph (3DSG) representations. To ensure the scalability of our approach, we: (1) exploit the hierarchical nature of 3DSGs to allow LLMs to conduct a semantic search for task-relevant subgraphs from a smaller, collapsed representation of the full graph; (2) reduce the planning horizon for the LLM by integrating a classical path planner and (3) introduce an iterative replanning pipeline that refines the initial plan using feedback from a scene graph simulator, correcting infeasible actions and avoiding planning failures. We evaluate our approach on two large-scale environments spanning up to 3 floors, 36 rooms and 140 objects, and show that our approach is capable of grounding large-scale, long-horizon task plans from abstract, and natural language instruction for a mobile manipulator robot to execute. We provide real robot video demonstrations and code on our project page sayplan.github.io.
paper: https://arxiv.org/pdf/2307.06135.pdf
Video: https://cdn-uploads.huggingface.co/production/uploads/6258561f4d4291e8e63d8ae6/d_U_pzeCoJ2dTcBWz6n0r.mp4

Bard is available in new places and languages
-
What: Bard is now available in over 40 new languages including Arabic, Chinese (Simplified/Traditional), German, Hindi, Spanish, and more. We have also expanded access to more places, including all 27 countries in the European Union (EU) and Brazil.
-
Why: Bard is global and is intended to help you explore possibilities. Our English, Japanese, and Korean support helped us learn how to launch languages responsibly, enabling us to now support the majority of language coverage on the internet.
Google Lens in Bard
-
What: You can upload images alongside text in your conversations with Bard, allowing you to boost your imagination and creativity in completely new ways. To make this happen, we’re bringing the power of Google Lens into Bard, starting with English.
-
Why: Images are a fundamental part of how we put our imaginations to work, so we’ve added Google Lens to Bard. Whether you want more information about an image or need inspiration for a funny caption, you now have even more ways to explore and create with Bard.
Bard can read responses out loud
-
What: We’re adding text-to-speech capabilities to Bard in over 40 languages, including Hindi, Spanish, and US English.
-
Why: Sometimes hearing something aloud helps you bring an idea to life in new ways beyond reading it. Listen to responses and see what it helps you imagine and create!
Pinned & Recent Threads
-
What: You can now pick up where you left off with your past Bard conversations and organize them according to your needs. We’ve added the ability to pin conversations, rename them, and have multiple conversations going at once.
-
Why: The best ideas take time, sometimes multiple hours or days to create. Keep your threads and pin your most critical threads to keep your creative process flowing.
Share your Bard conversations with others
-
What: We’ve made it easier to share part or all of your Bard chat with others. Shareable links make seeing your chat and any sources just a click away so others can seamlessly view what you created with Bard.
-
Why: It’s hard to hold back a new idea sometimes. We wanted to make it easier for you to share your creations to inspire others, unlock your creativity, and show your collaboration process.
Modify Bard’s responses
-
What: We’re introducing 5 new options to help you modify Bard’s responses. Just tap to make the response simpler, longer, shorter, more professional, or more casual.
-
Why: When a response is close enough but needs a tweak, we’re making it easier to get you closer to your desired creation.
Export Python code to Replit
-
What: We’re continuing to expand Bard’s export capabilities for code. You can now export Python code to Replit, in addition to Google Colab.
-
Why: Streamline your workflow and continue your programming tasks by moving Bard interactions into Replit.
-
- • 100%
Meta's new AI model aims to break the dominance of OpenAI and GPT-4 (article from 13.07.2023)
the-decoder.com Meta's new AI model aims to break the dominance of OpenAI and GPT-4With LLaMA V2, Meta may be trying to benefit from the open-source community, similar to what Google has done with Android.

>With LLaMA V2, Meta may be trying to benefit from the open-source community, similar to what Google has done with Android. > >The Financial Times, citing three sources familiar with the project, reports that Meta wants to launch a commercial AI model to compete with OpenAI, Microsoft, and Google. The model is said to generate language, code, and images. > >It may be a new variant of Meta's LLaMA, a large language model used in numerous open-source projects. LLaMA v1 has only been released under a research license and therefore may not be used directly for commercial purposes. However, replicas exist. > >Meta CEO Mark Zuckerberg has already announced that a new AI model is in the works, which could be LLaMA v2 or under a different name. Meta wants to use the model for its services and offer it to external interested parties, according to Zuckerberg. Special attention is safety.
- www.cnbc.com FTC investigating ChatGPT-maker OpenAI for possible consumer harm
The civil investigative demand asks OpenAI to explain how it obtains information to train its large language models.

Comment
stolenborrowed from reddit:>TL;DR: The Federal Trade Commission (FTC) is investigating OpenAI, the maker of ChatGPT, for potential violations of consumer protection laws. The investigation will focus on whether OpenAI has engaged in unfair or deceptive privacy or data security practices, or if it has engaged in unfair or deceptive practices relating to risks of harm to consumers. The FTC has asked OpenAI to provide information on how it obtains and uses consumer information to train its large language models, how it assesses risk, and how it deals with misleading or disparaging statements about people. The FTC is also seeking information about a bug disclosed by OpenAI in March 2020 that may have exposed some users' chat history and payment-related information. OpenAI has not yet responded to the investigation.
- www.maginative.com OpenAI and AP are Partnering to Explore Generative AI and the Future of News
The partnership sets both companies on an ambitious course to integrate generative AI in journalism and news production, with implications that could redefine the industry.

>The Associated Press (AP) and OpenAI have announced a new partnership that seeks to examine potential use cases for generative AI in news products and services. As part of the arrangement, OpenAI will license part of AP's text archive and, in return, AP will tap into OpenAI's advanced technology and product expertise.
Like without any human interventions. What would our routine be like?
- news.mit.edu Generative AI imagines new protein structures
MIT CSAIL researchers created FrameDiff, a computational tool utilizing machine learning to design novel protein structures. By simulating protein backbones with mathematical frames, FrameDiff constructs proteins that surpass natural varieties.

- stability.ai Clipdrop Launches Stable Doodle — Stability AI
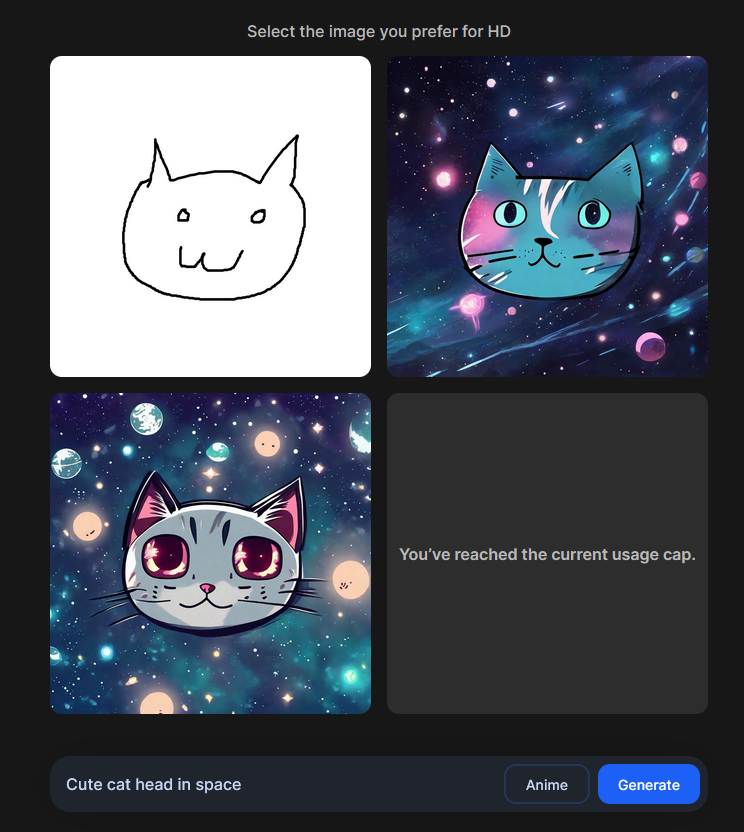
Stability AI launches Stable Doodle, a sketch-to-image tool that converts a simple drawing into a dynamic image, providing limitless imaging possibilities to a range of professionals and hobbyists.

Stability AI launches a web tool that allows you to turn your doodles into pretty AI-generated images: https://clipdrop.co/stable-doodle
It's not clear what the free daily limit is, but it seems to be about 3 prompts every hour. Results are pretty neat.
!A crude drawing of a cat's head prompted: a picture of a cat head in space. The results are good.
>While firms’ adoption of AI is still relatively low, rapid progress including with generative AI (e.g. ChatGPT), falling costs and the increasing availability of workers with AI skills suggest that OECD countries may be on the brink of an AI revolution. It is vital to gather new and better data on AI uptake and use in the workplace, including which jobs will change, be created or disappear, and how skills needs are shifting. When considering all automation technologies including AI, 27% of jobs are in occupations at high-risk of automation. Initial findings from a new OECD survey of AI's impact in the manufacturing and finance sectors of seven countries highlight both the opportunities and risks that AI brings.
We really need UBI, de-commodified housing, and medicare for all to stabilize society during the transition to post-singularity.
- www.digitaltrends.com Elon Musk's new AI company aims to understand the universe | Digital Trends
In an apparent bid to take on the likes of OpenAI, Elon Musk has launched a new AI company that seeks to understand the true nature of the universe.

TL;DR: (AI-generated 🤖)
The author, an early pioneer in the field of aligning artificial general intelligence (AGI), expresses concern about the potential dangers of creating a superintelligent AI. They highlight the lack of understanding and control over modern AI systems, emphasizing the need to shape the preferences and behavior of AGI to ensure it doesn't harm humanity. The author predicts that the development of AGI smarter than humans, with different goals and values, could lead to disastrous consequences. They stress the urgency and seriousness required in addressing this challenge, suggesting measures such as banning large AI training runs to mitigate the risks. Ultimately, the author concludes that humanity must confront this issue with great care and consideration to avoid catastrophic outcomes.
- bounded-regret.ghost.io What will GPT-2030 look like?
GPT-4 surprised many people with its abilities at coding, creative brainstorming, letter-writing, and other skills. How can we be less surprised by developments in machine learning? In this post, I’ll forecast the properties of large pretrained ML systems in 2030.

{kind=link}
{kind=link}
{kind=link}
{kind=link}