
No Stupid Questions (Developer Edition)
To my understanding:
Many terminals are capable of displaying multiple fonts at the same time, say latin unicode characters in font foo and japanese unicode characters in font baz. In urxvt at least, it is also possible to have one font in a certain size and the next font in another size. However, no font can have a size bigger than the base size, the size of a terminal cell.
Why is it not possible to have multiple terminal cell sizes? For exampleso one line has terminal size 8 and the next line has terminal size 12.
The wikipedia articles are terribly written (for math loves or people who just need to refresh their knowledge).
What is a "sum" of types? What is a product of types? Is it possible to
Cat x DogorCat + Dog? What does that even mean?So I want to build blender fork but it fails to build on Visual Studio 2022. There is already a patch and a open PR that fixes the issue.
I have already git cloned the repository and I would want to only get the patch into my local repository. So I can build from that.
Limitation of using drag and drop Images in readme.md?
One I am aware of is the size limit that no image size should be >10 MB. Are there any other limitations when using this (for example: retention period, storage capacity, etc)? I want to link those images outside Github.
I am aware of uploading images to the repository and linking by
[image](./path/to/image/image.png)You see this with some apps (I think ReVanced is a popular example?) and games occasionally, and I've never been clear on how they do it.
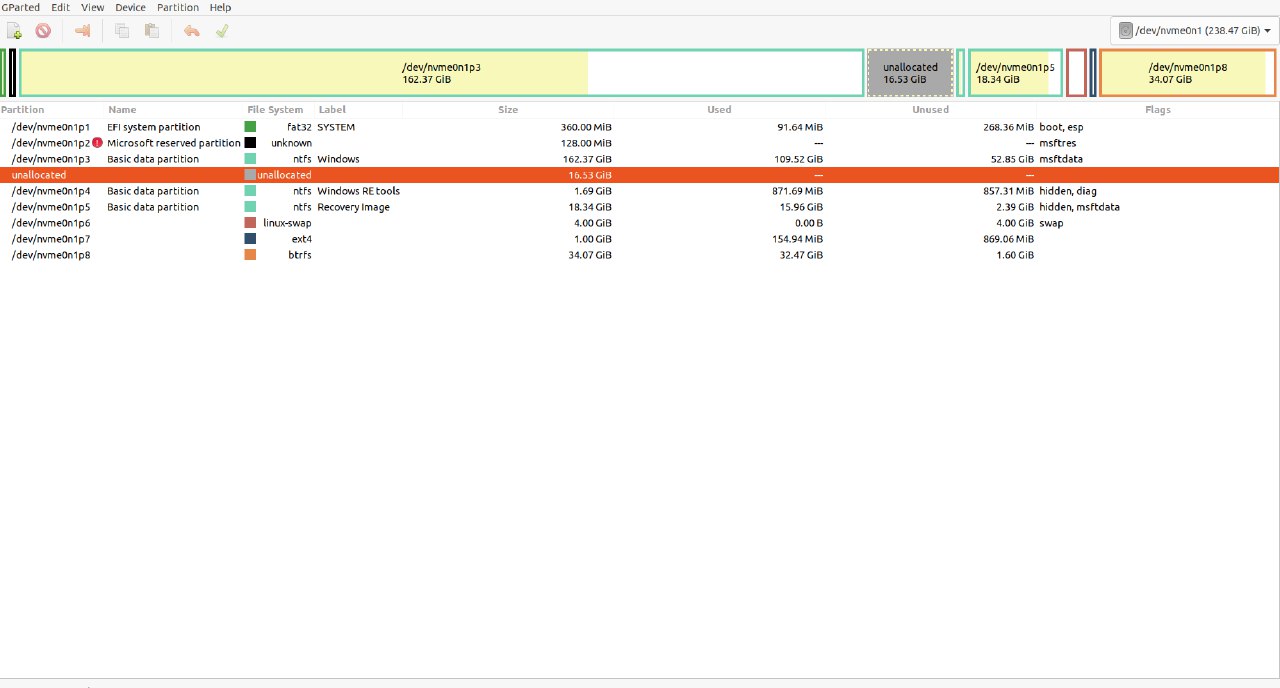
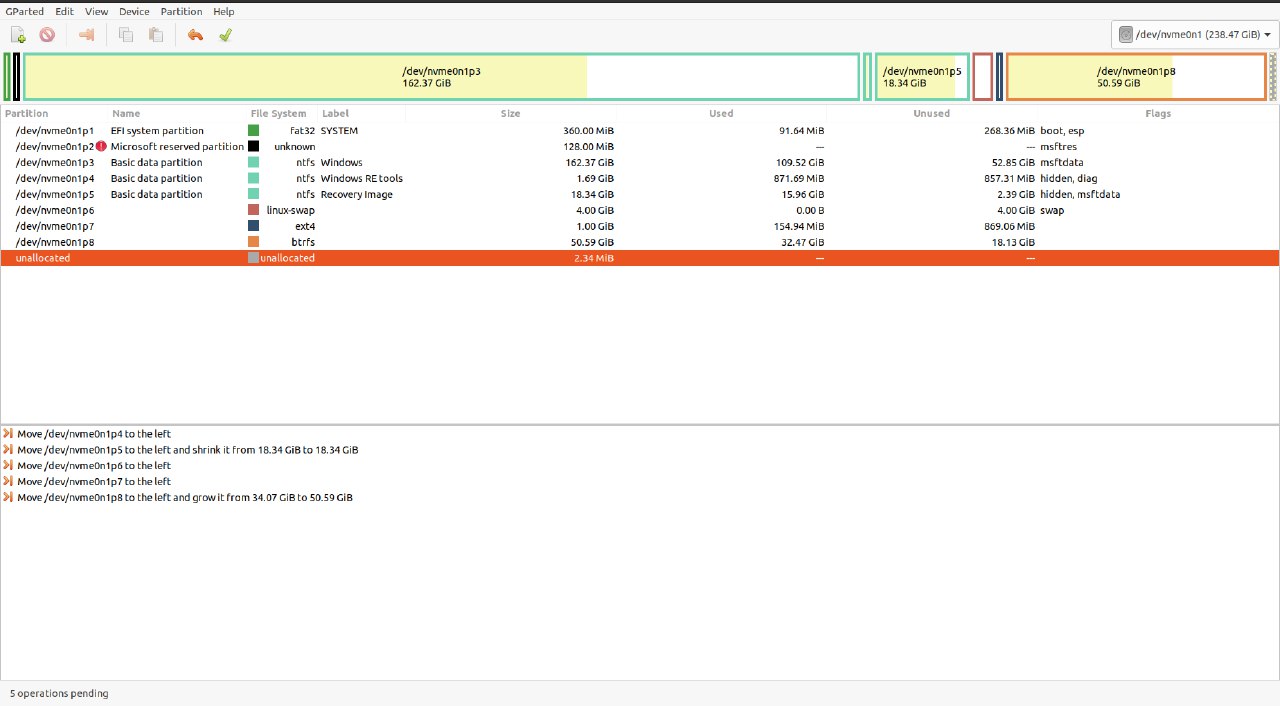
Hello. I have Windows - Ubuntu dual boot and I'm trying to move space from Windows to Ubuntu. I've already freed space from the Windows side
I'm pretty sure that I've read online that it can be dangerous to move the unallocated partition, because next boot to windows can corrupt my Ubuntu system. Is it true? Also, when I'm trying to move the unallocated partition, there's no option to "move/resize", so I swap them with the next following partition one by one. Is it the right way to do it?
So I'm a baby dev, still in Uni and they don't allow internships in 4th year due to some issues with it so not even that exp wise.
I don't know enough, and I'm trying to learn but there's so much! My Uni degree doesn't cover security at all. Which is shit, bc I think I want to work in that? Mostly I'm just spooked and want to understand everything I can 'cause I love the internet and want to feel safer wandering about it.
I'm scared of clicking on links. Even ones here, like there was a post about a book list earlier and I was just there like "Cmoon.... someone please have posted the lissssst."
Would anyone be willing to share what they do for their own security? Especially if it's ridiculously over the top. Included reasonings and details would be adored!
Also, if anyone has any books or references that might be good for learning sec from a programmatic view rather than a IT view I'd really love that! Anything at all.
Regardless, hope anyone reading this has an absolutely wonderful day and best of luck with everything you're up to!
Can't locally download 41 GB loaded image which is provided to replicate GitHub action locally but don't want to commit and check every time too, is there any third option?
- • 100%
Do containers only work on their relevant OS (i.e. Linux distro/MacOS/Windows) + container engine?
I think from what I've read that this is the case, but I've read some other info that's made it less clear to me.
On the second part of the question regarding container engines, I'm pretty sure that may also be correct, and it kinda makes me wonder a little about risks of engine lock-in, but that may be a little out of scope.
cross-posted from: https://programming.dev/post/6513133
> Short explanation of the title: imagine you have a legacy mudball codebase in which most service methods are usually querying the database (through EF), modifying some data and then saving it in at the end of the method. > > This code is hard to debug, impossible to write unit tests for and generally performs badly because developers often make unoptimized or redundant db hits in these methods. > > What I've started doing is to often make all the data loads before the method call, put it in a generic cache class (it's mostly dictionaries internally), and then use that as a parameter or a member variable for the method - everything in the method then gets or saves the data to that cache, its not allowed to do db hits on its own anymore. > > I can now also unit test this code as long as I manually fill the cache with test data beforehand. I just need to make sure that i actually preload everything in advance (which is not always possible) so I have it ready when I need it in the method. > > Is this good practice? Is there a name for it, whether it's a pattern or an anti-pattern? I'm tempted to say that this is just a janky repository pattern but it seems different since it's more about how you time and cache data loads for that method individually, rather than overall implementation of data access across the app. > > In either case, I'd like to learn either how to improve it, or how to replace it.
What are some alternatives to browsing instagram "outside" of the proper app?
I put nitter.net and invidious as examples, as they allow you to browse Twitter and Youtube "outside" the official site/app and without being tracked. Instagram hates me trying to look at anything from the computer.
I need an open-source AI front-end (use with openai api key) with following option:
- Do web search
- Chat with document as context
- More Plugin
Please suggest me some open-source project that work.
I have 5 years experience as full time job.
However I never do freelancer job before.
How do I start on finding freelancer job ?
It is a common sentiment that managing dependencies is always a big issue in software development and the reason why so many apps come pre-bundled with all the requirements so it reliably works on every machine.
However, I don't actually understand why is that an issue and why people generally bash npm and the way it's done there. Isn't it the simplest and most practical solution to a problem - you have a file which defines which other libraries you need, which version, and then with one command you can install them and run the program?
Furthermore, those libraries and their specific versions can be stored elsewhere and shared across all apps on a system so you can easily reuse them instead of having to redownload for each program individually.
I must be missing something since if it were that easy, people would have solved it years ago and agreed on a standardized best way, so I'm wondering what is the actual issue and a cause of so many headaches.
In CSS, let's talk about srcset or image-set. In that context, you can define which image the browser loads using 1x, 2x, 3x, etc. These refer to pixel density. (In the case of srcset, you can use pixel dimensions too, which sidesteps the issue I'm going to talk about, but it still occurs in image-set, and also is still weird to me in srcset, even if you can side step it.)
So, assuming, say, a 20" monitor with 1080p resolution is 1x, then a 10" screen with 1080p would be, technically, 2x - though, in the real world, it's more like a 6" screen has a 1000x2500 resolution - so, I don't care about math, that's somewhere between 2x and 3x.
Let's imagine a set of images presented like this:
srcset(image_1000x666.webp 1x, image_1500x1000.webp 2x, image_3000x2000.webp 3x)then an iphone 14 max (a 6"-ish screen with a 1000x2500-ish resolution, for a 2-3x pixel density), would load the 3000x2000 image, but my 27", 1440p monitor would load the 1000x666px image.
It seems intuitively backwards - but I've confirmed it - according to MDN, 1x = smaller image, 3x = larger image.
But as I understand it, an iphone 14 acts as if its a 300x800 screen - using the concept of "points" instead of pixels - which, in the context of "1x" image size makes a lot of sense - but the browser isn't reading that, all it seems to care about is how many pixels are in an inch.
I made a little page to demonstrate the issue, tho I acknowledge it's not hugely helpful, since, other than using your actual eyeballs, it's hard to tell which image is loaded in the scrset example, but take a look if you want.
https://germyparker.github.io/image-srcset-example/
After some time of practicing PyQt I found out about Kivy, as a beginner which one can be considered with an "easier" syntax to learn? After several days of practicing PyQt I feel I would be throwing away my learning for Kivy.
PyQt is not that complex really but what I hate with all my heart is using Qt Designer and then exporting that to a .py file, I really don't like the way it formats the text, but that's just a personal detail. I know I can perfectly do it manually but all the tutorials and I mean ALL of them always do it in that way.
I want to clarify that I'm interested in Android application development, that's really a strong point for me of Kivy.
I've been learning Python by myself for about 3 years now and I can say that I know quite a lot but I don't really feel confident in my own programming skills and always after a while of practicing or reviewing I end up quitting because I feel exactly this.
I don't know how to explain it, but I really feel like I'm in a cycle repeating the same noob exercises over and over again.
For example, lately I have been practicing a lot PyQt but I really feel that I am wasting time when I don't learn a new concept or I don't memorize something and I need to look at my notes to remember how to do it, and also that practicing with online courses, especially with Youtube is often a challenge because the authors do things differently and I get confused by that. And when I want to learn something new the amount of information overwhelms me and I feel tired because of that.
As a Linux user I know that what I just said is stupid, because for example it is impossible to learn all the commands in the world, you just really learn the ones you use most regularly but in programming I feel that for example asking ChatGPT (or any ChatBot) counts as cheating for some reason, I don't know how to explain it.
I really consider this probably a mentality problem more than a skill problem because honestly even though I know I can I don't feel sure how to program, many times I even doubt the name of my variables or my functions.
Thanks for reading my silly post!
Note that I'm using autohotkey v2, not v1.
I want to run two different autohotkey scripts. I want to trigger a hotstring in the first script, the output of which ends up being part of the hotstring trigger for the second script. Is this possible?
Here's a simplified version of my intended workflow.
Script 1:
#Hotstring EndChars \ #Hotstring o #Hotstring ? ::iv::ǐ ::av::ǎScript 2:
#Hotstring EndChars \ #Hotstring o #Hotstring ? ::nǐ::你 ::hǎo::好So the idea is that I can type niv\ and the first script will convert it to nǐ - then I can immediately type \ and the second script will convert it to 你. So I type niv\\\ and my text goes from niv to nǐ to 你. I can then type hav\o\ and have my text go: h, ha, hav, hǎ, hǎo, 好. So I can do niv\ hav\o and get nǐ hǎo, or I can do niv\\\ hav\o\ and get 你 好. Both writing systems in a reasonably simple format.
There are reasons I want to set it up like this. The first script has dozens of functions beyond writing in pinyin/chinese, and I share it with another person - so I don't want to add potentially hundreds of random Chinese hotstrings to it, just the special pinyin characters. That's why I'm using two scripts.
But I also realize I could just make "niv" and "havo" their own hotstrings which go directly to 你 and 好 without the intermediate nǐ and hǎo. I don't want to do this mostly because I think the system I have in mind is prettier - type it correctly in pinyin first, then have it correctly convert to Chinese.
All of that aside: I've gathered that this is probably possible using some combination of SendLevel and #InputLevel - but I've tried a bunch of different combinations and ideas with it, and haven't successfully had one script trigger another yet. Even in simplified toy scripts, which is a little discouraging. Ideally I'd be able to do this with as few changes to the main script I share with another person as possible - the script that handles the Chinese can be as complicated as it needs to be though. Anyone know how to make this work?
Know this isn't technically Dev, sorry in advance.
I keep getting outbound malware alerts when I browse global. Today it's lemmy.today, last week it was another instance etc.
I'm interested in learning more about sec, and while I've looked at the JSON logs and tried googling "What does threat id -1 mean" etc., I can't seem to find anything.
I'm kind of just curious about what, specifically, the threat was and what it was trying to do - but the logs seem pretty blank. As mentioned above, the id is -1 and the name is blank.
Anyone know a good guide, or something, to read up or... better questions to ask?
Thank you for your time and hav a wonderful day. :)
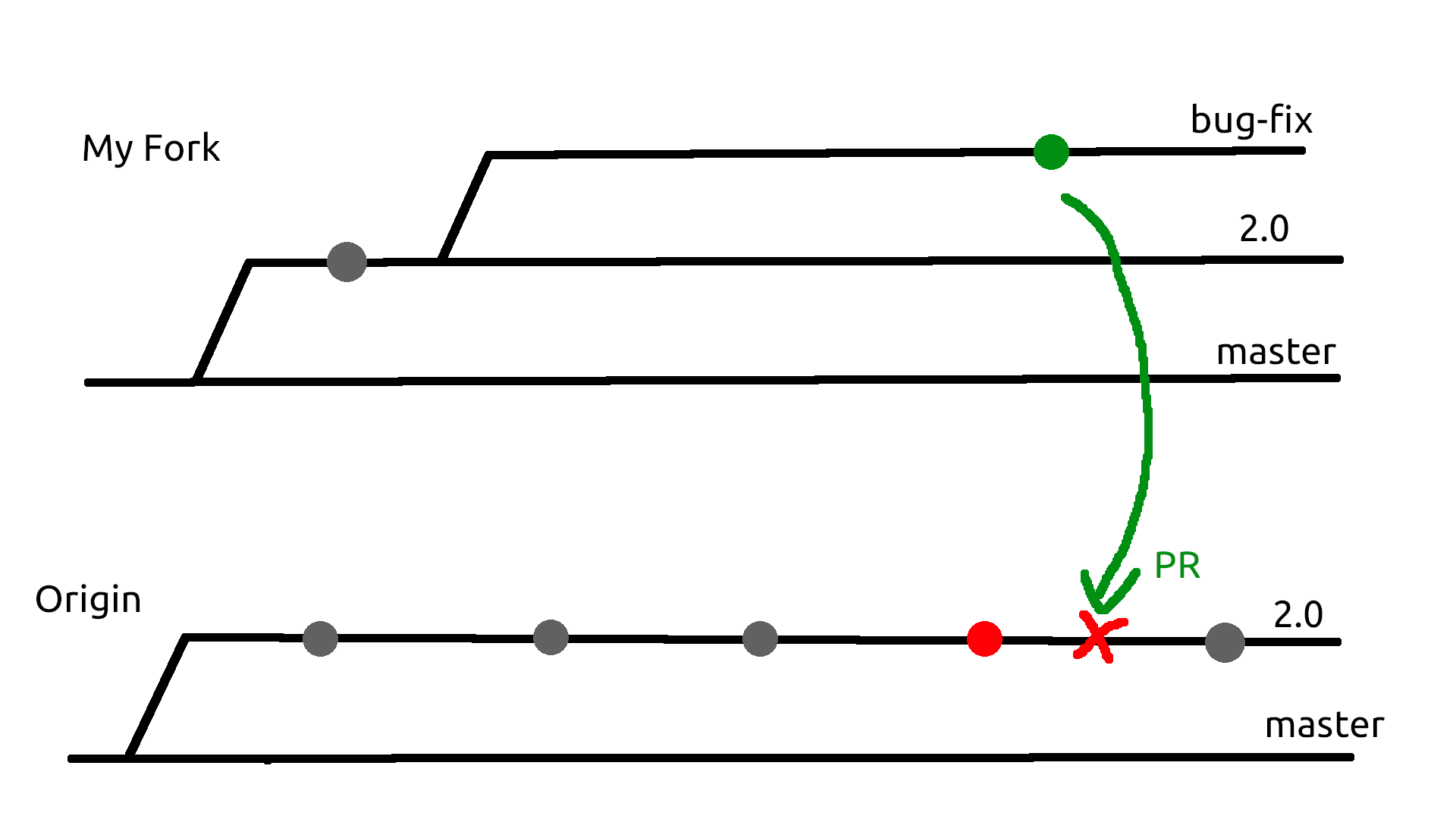
!drawing showing git history made in gimp
So I have a bug fix (green) and owner also made a bug fix (red) but I would like to rework both of them due to discussion we had. I have opened a PR and there is merge conflict that can't be resolved. Should I open a new branch in my fork and close PR or should I google some rebase magic to apply commits to my bug-fix branch.
I'm aware this has been the case since Windows 3.x, you always need an external program to ensure the executable is created with the icon you want. Why?
Please no mentions of Linux and other OSs, I know it's trivial to do so for them.
Do I master Typescript if I master Javascript ? Is Typescript syntax different ? Answers appreciated, thank you !
Hi, I'm using a MacBook Pro 2018, and I'm dipping my toes into virtual machine, tried VirtualBox and then moved to QEMU with UTM after some recommendation on YouTube saying KVM is just better.
However, my Windows 10 virtual machine created with UTM is so slow and laggy. Then I tried the Parallel Desktop, which is propriety and the performance is so much better. Why is that?
I don't want to use a propriety paid program for VM, so I want to ask how to improve performance on UTM or any open-source alternative that gives the performance on par with one on parallel desktop.
cross-posted from: https://programming.dev/post/993501
> I use manjaro linux and I installed brave using the AUR repo. I keep hearing stories about how Brave is just another ad tracking software like Chrome. What I don't understand is why, like specifically. > > Because I downloaded Brave from here. The code for Brave is here. I can build and install Brave and it will be the same as from AUR right? > > Ok let me list my questions: > > 1. If the sourcecode for Brave is open and is all I need to compile and run the software then where's the tracker. The code base is honestly to big and high level for me and my professional abilities but I'm not that great of a programmer, I'm just really good. If there are ad trackers or adblock-blockers then I should beable to see it in the code right? I just need help actually seeing these lines of code. > 2. I've used wireshark to monitor Brave in isolation and I couldn't see traffic that I would disapprove of. It is also very realistic that I just don't know how to recognize. > 3. Just because Google maintains chromium doesn't mean that chromium browsers have to track you. Chromium is opensource and it shouldn't cost much to comment out trackers. So wasn't this already done? And if not can we actually see the lines of code that track us? > > Really what I'm looking for is help coming to the conclusion that these browsers are that bad for me myself.
Or, put it another way, a html renderer that can open most web pages, but has a different programming/scripting language that it can interpret during runtime or on page loads, instead of the javascript engine.
I suppose that java applets, flash and activeX were attempts in these directions, but they were things you had to install on top of the browsers, so not quite the same thing? I'm imagining something like web pages using Lua, since it's lightweight, to make them dynamic.
I just started learning c++. I installed visual studio with "Desktop Development with C++". CPlusPlus.com shows info for different c++ versions. How can I check which one I am using?
I'm still getting the hang of Lemmy and federated services.
I'm browsing the programming.dev instandce in the Liftoff app and I can choose to view:
- my subscribed communities on the server (currently none)
- Local communities on the server
- All (?)
I know All is not "all communities on Lemmy" but what perplexes me is I can see posts from another community that is hosted on a different server and it appears because it is "via programming.dev".
At first I thought it was because a user registered on " programming.dev " posted on another instance but I opened my eyes and saw the user's origin is no way related.
Any ideas?
EDIT:
After reading all the comments I’m pretty sure “via programming.dev” should read in the context of the post as
!community@instanceis knownvia programming.devinstance. I guess it makes it explicit which “all” I am browsing if I pick up browsing where I left off and forget I am not in the “all local”.At this point I have only seen this on the Liftoff App for Lemmy but still trying other. Must be in the metadata and Liftoff decided to display it.
I created a Lemmy instance. Making posts, comments, all that jazz seems to be good. Sign up works. Other functions work. What doesn't work is federation. The instance is been alive about about 24hours and I don't see anything in the all tab. Directly going to communities via a url like "my.lemmy.instance/c/sub@other.instance" shows the external community's sidebar, bur not the posts I know exist.
I haven't added anything to the allow or block list and federation is turned on. Have I missed something or is it just a matter of waiting a little more?
Because I'm in my very early 20s I missed out on the huge Java craze. Everything was Python when I started getting a more formal education and before then all my work was in C++. Knowing more languages would obviously look better on a CV but I mean if I would benefit in a practical sense? I have two friends who are long time Java devs. And recently another friend who generally works with legacy C++ based systems from the early 2000s late 90s period had to work on a bunch of stuff in Java. Java is clearly still in large scale use among older systems. So would it be likely that eventually I would need to work on Java systems myself when my job is mostly JavaScript currently?
Hello, I currently have just a little experience with asp.net and rest api's, but most of my development is windows desktop apps. I'd like to learn a javascript framework (angular, react, vue, or next.js are some I've looked at) and I was wondering if anyone knows of a good tutorial for using one.
#1 - Is there a general search function, not just for communities.
#2 - Is there a subscriptions view
This is a place where you can ask any programming related questions you want!
For a more general version of this concept check out !nostupidquestions@lemmy.world
{kind=link}
{kind=link}
{kind=link}