SQL
I am one of the developers on a very small team and have just found the following query
I would love to hear your ideas for what you think was being attempted here!
SELECT ... FROM client WHERE CAST(ABS(SIN(clientId)) AS BIT) = 0- gist.github.com Modern SQL Style Guide
Modern SQL Style Guide. GitHub Gist: instantly share code, notes, and snippets.

I found this SQL style guide which looks good. I'm not a pro at SQL but it looks good to me. I mean, you use the style guide your boss wants you to use, or what all others use, but what if you could choose?
>TL;DR? > > PRAGMA journal_mode = WAL; > PRAGMA busy_timeout = 5000; > PRAGMA synchronous = NORMAL; > PRAGMA cache_size = 1000000000; > PRAGMA foreign_keys = true; > PRAGMA temp_store = memory ;
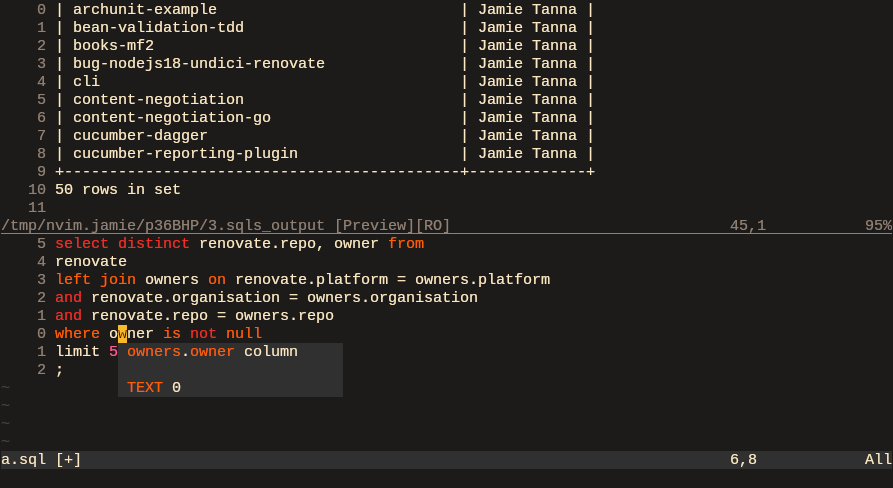
- www.jvt.me My workflow for writing SQL(ite) queries (2024 edition) · Jamie Tanna | Software Engineer
Writing about my recent workflow for writing, executing, and sharing SQL queries with others.
- www.citusdata.com POSETTE: An Event for Postgres 2024
Join us at POSETTE: An Event for Postgres (formerly Citus Con), a virtual and free developer event happening on Jun 11-13, 2024. Come learn what you can do with the world’s most advanced open source relational database—from the nerdy to the sublime. Organized by the Postgres team at Microsoft.

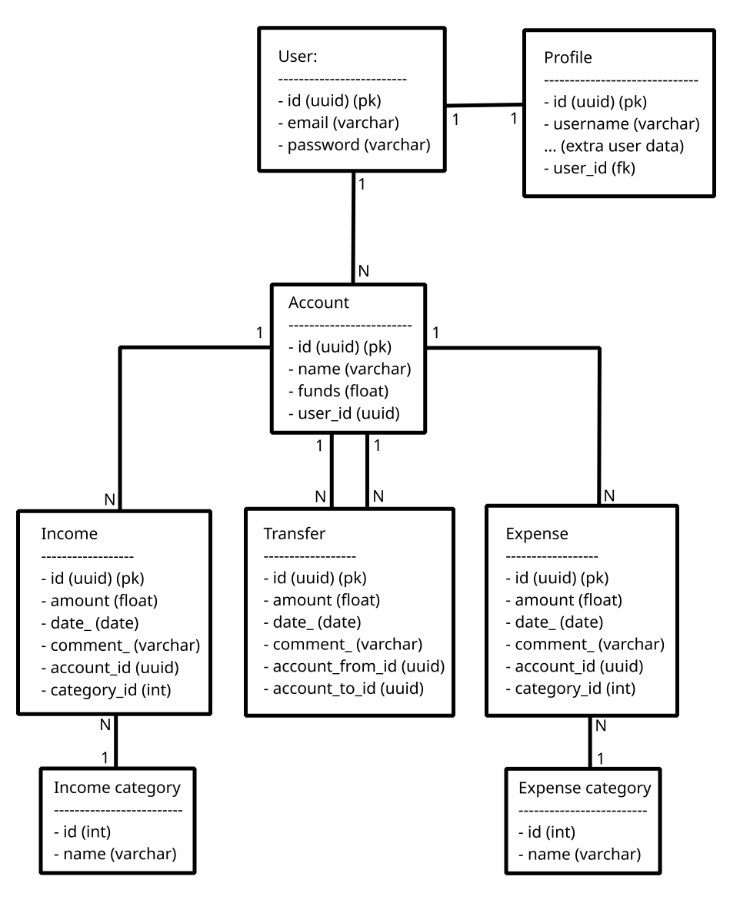
Hello! Let me first clarify, this is for a personal project, based on an idea I always use to learn all kinds of things: personal finance tracking.
The DB model I typically use looks something like this:
Initially, I made the decision to separate incomes, expenses and transfers into separate tables, which makes sense to me, according to the way I learned DB normalization.
But I was wondering if there is any benefit in somehow mixing the expense and income tables (since they are almost identical, and any code around these is always almost identical), or even all 3 (expense, income and transfer). Maybe it is more convenient to have the data modeled like this this for an API, but for BI or analytics, a different format would be more convenient? How would such format look like? Or maybe this would be better for BI and analytics, but for an API it's more convenient to have something different?
A while ago at a previous job, an experienced software architect once suggested, for a transactional system, to separate the transactional DB from a historical DB, and continuously migrate the data differences through ETL's. I have always thought that idea is pretty interesting, so I wonder if it makes sense to try in my little personal project.
If it was you, how would you model personal finance tracking? Is there something you think I may be missing, or that I should look into for DB modeling?
(Note: I intentionally do not track loans / investments, or at least I have not tried to integrate it for the sake of simplicity, and I have no interest in trying YET.)
Is there a programming language specifically designed for interacting with SQL databases that avoids the need for Object-Relational Mappers (ORMs) to solve impedance mismatch from the start?
If such a language exists, would it be a viable alternative to PHP or Go for a web backend project?
- digma.ai How to Optimize Slow SQL Queries
Get insights using real-life examples on how to identify and optimize slow SQL queries when working with PostgreSQL, MySQL, MSSQL, Oracle.

cross-posted from: https://programming.dev/post/10749238
> cross-posted from: https://programming.dev/post/10707322 > > > cross-posted from: https://programming.dev/post/10707319 > > > > > In this article, we want to share our experience with fellow developers and offer insights using real-life examples on how to identify and optimize slow SQL queries, especially when working with relational database management systems like PostgreSQL, MySQL, MSSQL, Oracle, etc.
- • 100%
intended audience
- Rachel has a master’s degree in cell biology and now works in a research hospital doing cell assays.
- She learned a bit of R in an undergrad biostatistics course and has been through the Carpentries lesson on the Unix shell.
- Rachel is thinking about becoming a data scientist and would like to understand how data is stored and managed.
- Her work schedule is unpredictable and highly variable, so she needs to be able to learn a bit at a time.
prerequisites
- basic Unix command line: cd, ls, * wildcard
- basic tabular data analysis: filtering rows, aggregating within groups
learning outcomes
- Explain the difference between a database and a database manager.
- Write SQL to select, filter, sort, group, and aggregate data.
- Define tables and insert, update, and delete records.
- Describe different types of join and write queries that use them to combine data.
- Use windowing functions to operate on adjacent rows.
- Explain what transactions are and write queries that roll back when constraints are violated.
- Explain what triggers are and write SQL to create them.
- Manipulate JSON data using SQL.
- Interact with a database using Python directly, from a Jupyter notebook, and via an ORM.
I’ve started to take an intro SQL class but I want to find more places to practice. Do any of you have recommendations for sites that I can use to practice creating queries based on pieces of information someone is looking for?
Any other advice to give to a brand new SQL learner?
Thanks in advance for any guidance.
Edit: Thanks a ton for the responses, I really appreciate it. I’ve bookmarked these pages and started to go through these sites.

- • 100%github.com Fix Posts List Performance + cursor-based pagination by phiresky · Pull Request #3872 · LemmyNet/lemmy
This PR implements two things: Cursor-based pagination for the /posts/list API request. A new opaque parameter page_v2 is added that fetches the next page based on the previous one. The request n...
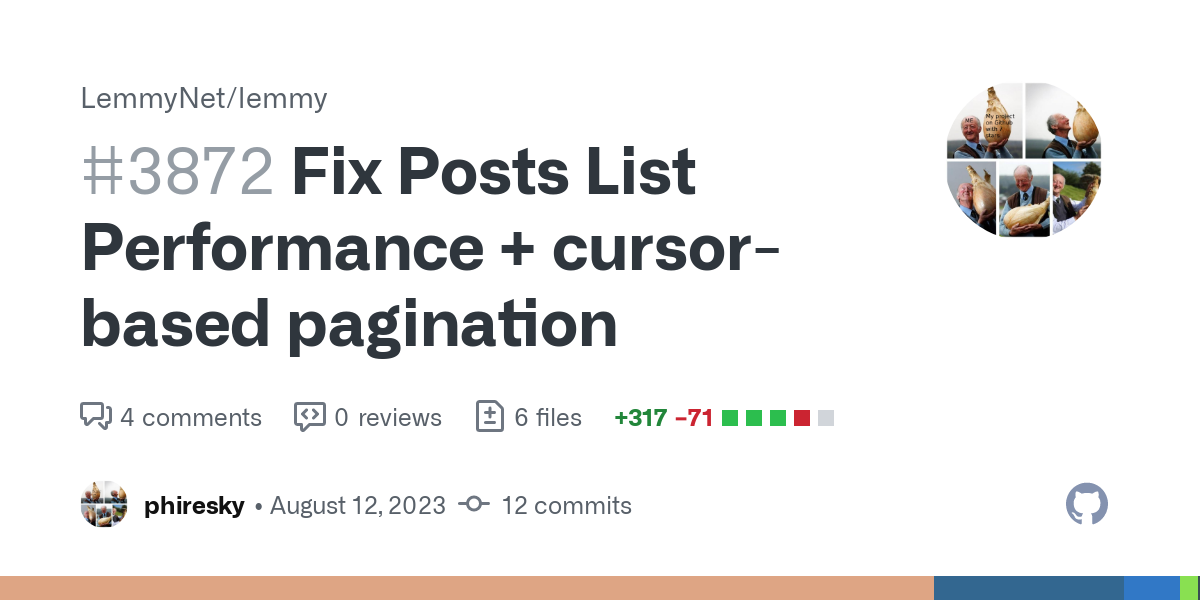
Looks like @phiresky@lemmy.world is looking for reviews on their latest optimizations to the Lemmy backend. Figured folks here might be interested in taking a look.
- • 100%alexplescan.com Timeseries with PostgreSQL
How to use set-returning functions in PostgreSQL to generate simple timeseries data

A relatively simple but common application of time series done with PG.
cross-posted from: https://programming.dev/post/700753
> I tried looking the original Joint USSS/FBI Advisory shown in the end of the video, and found these: > - https://web.archive.org/web/20150910021244/https://usa.visa.com/download/merchants/20090212-usss_fbi_advisory.pdf > - https://www.researchgate.net/publication/346975125_Heartland_Data_Breach_Analysis
- peter.eisentraut.org SQL:2023 is finished: Here is what’s new
SQL:2023 has been wrapped. The final text has been submitted by the working group to ISO Central Secretariat, and it’s now up to the ISO gods when it will be published. Based on past experience, it could be between a few weeks and a few months.
- github.com GitHub - saulpw/visidata: A terminal spreadsheet multitool for discovering and arranging data
A terminal spreadsheet multitool for discovering and arranging data - GitHub - saulpw/visidata: A terminal spreadsheet multitool for discovering and arranging data
cross-posted from: https://programming.dev/post/252619
> Works with Postgresql, MySql, and SQLite natively. > > Extends confirmed support for DuckDB, ClickHouse, BigQuery, and Snowflake via the vdsql plugin.
- mystery.knightlab.com SQL Murder Mystery
Use SQL queries to solve the murder mystery. Suitable for beginners or experienced SQL sleuths.

> Can you find out whodunnit?
- postgresql.life Interview with: Ryan Booz | PostgreSQL Person of the Week
PostgreSQL Person of the Week interview with Ryan Booz, published 15.05.2023, interview conducted by Andreas Scherbaum

- postgresql.life Interview with: Floor Drees | PostgreSQL Person of the Week
PostgreSQL Person of the Week interview with Floor Drees, published 08.05.2023, interview conducted by Andreas Scherbaum

{kind=link}