datahoarder
Just looking at the numbers, it doesn't seem to me like archival will complete before the shutdown date (nov. 11). There are 2million+ elements left, likely 100TB+ of videos.
If you care to help them out, see instructions at the top of the page. Be sure you have a "clean connection", though.
edit: They're saying that the current rate seems to be plenty enough to finish by the deadline. Workers are often left idling at the moment.
cross-posted from: https://lemmy.world/post/21563379
> Hello, > > I'm looking for a high resolution image of the PAL cover from the Dreamcast (I believe). > > There was this website covergalaxy that used it have in 2382x2382 but all the content seems to be gone. Here's the cache https://ibb.co/nRMhjgw . Internet archive doesn't have it. > > Much appreciated! >
The September 17th archive of the oldest public video on ashens' channel is saved with the comments section of a completely different video.
(only loads on desktop for me)
Not sure how this happened, usually it's no comments section at all.
If I were trying to make a point here: an archive doesn't even have to be malicious to contain misleading information presented as fact.
I did try to read the sidebar resources on https://www.reddit.com/r/DataHoarder/. They're pretty overwhelming, and seem aimed at people who come in knowing all the terminology already. Is there somewhere you suggest newbies start to learn all this stuff in the first place other than those sidebar resources, or should I just suck it up and truck through the sidebar?
EDIT: At the very least, my goal is to have a 3-2-1 backup of important family photos/videos and documents, as well as my own personal documents that I deem important. I will be adding files to this system at least every 3 months that I would like incorporated into the backup. I would like to validate that everything copied over and that the files are the same when I do that, and that nothing has gotten corrupted. I want to back things up from both a Mac and a Windows (which will become a Linux soon, but I want to back up my files on the Windows machine before I try to switch to Linux in case I bungle it), if that has any impact. I do have a plan for this already, so I suppose what I really want is learning resources that don't expect me to be a computer expert with 100TB of stuff already hoarded.
I download lots of media files. So far I have been storing these files after I am done with them on a 2TB hard disk. I have been copying over the files with rsync. This has so far worked fairly well. However the hard disk I am using is starting to get close to full. Now I am needing to find a solution so I can span my files over multiple disks. If I were to continue to do it as I do now, I would end up copying over files that would already be on the other disk. Does the datahoading community have any solutions to this?
For more information, my system is using Linux. The 2TB drive is formatted with ext4. When I make the backup to the drive I use ’rsync -rutp’. I don’t use multiple disks at the same time due to having only one usb sata enclosure for 3 1/2 inch disks. I don’t keep the drive connected all the time due to not needing it all the time. I keep local copies until I am done with the files (and they are backed up).
Hey everyone,
it’s me again, one of the two developers behind GameVault, a self-hosted gaming platform similar to how Plex/Jellyfin is for your movies and series, but for your game collection. If you've hoarded a bunch of games over the years, this app is going to be your best friend. Think of it as your own personal Steam, hosted on your own server.
If you haven’t heard of GameVault yet, you can check it out here and get started within 5 minutes—seriously, it’s a game changer.
For those who already know GameVault, or its old name He-Who-Must-Not-Be-Named, we are excited to tell you we just launched a major update. I’m talking a massive overhaul—so much so, that we could’ve rebuilt the whole thing from scratch. Here’s the big news: We’re no longer relying on RAWG or Google Images for game metadata. Instead, we’ve officially partnered with IGDB/Twitch for a more reliable and extended metadata experience!
But it doesn’t stop there. We’ve also rolled out a new plugin system and a metadata framework that allows you to connect to multiple metadata providers at once. It’s never been this cool to run your own Steam-like platform right from your good ol' 19" incher below your desk!
What’s new in this update?
- IGDB/Twitch Integration: Say goodbye to unreliable metadata scrapers. Now you can enjoy game info sourced directly from IGDB.
- Customizable Metadata: Edit and fine-tune game metadata with ease. Your changes are saved separately, so the original data stays intact.
- Plugin System: Build your own plugins for metadata or connect to as many sources as you want—unlimited flexibility!
- Parental Controls: Manage age-appropriate access for the family and children.
- Built-in Media Player: Watch game trailers and gameplay videos directly in GameVault.
- UI Overhaul: A fresh, streamlined look for the app, community, game and admin interface.
- Halloween Theme: For GameVault+ users, we’ve added a spooky Halloween skin just in time for the season!
Things to keep in mind when updating:
- GameVault Client v1.12 is now required for servers running v13 or above.
- Older clients won’t work on servers that have been updated to v13.
For a smooth update and a guide on how to use all these new features, check out the detailed migration instructions in the server changelogs. As always, if you hit any snags, feel free to reach out to us on Discord.
If you run into any issues or need help with the migration, feel free to join and open a ticket in our Discord community—we’re always happy to help!
If you want to support our pet-project and keep most upcoming features of GameVault free for everyone, consider subscribing to GameVault+ or making a one-time donation. Every little bit fuels our passion to keep building and improving!
Thanks for everything! We're more than 800 Members on our discord now and I can’t wait to hear what you think of the latest version.
I know for photos i could throw them through something like Converseen to take them from .jpg to .jxl, preserving the quality (identical visially, even when pixel peeping), but reducing file size by around 30%. What about video? My videos are in .h265, but can i reencode them more efficiently? im assuming that if my phone has to do live encoding, its not really making it as efficient as it could. could file sizes be reduced without losing quality by throwing some processing time at it? thank you all
Yoko Taro is the creative director behind the Nier and Drakengard series, and he has released a lot of supplemental material across a variety of mediums over the years in Japan. Accord's Library is a site that is dedicated to finding this material, archiving it, and translating it.
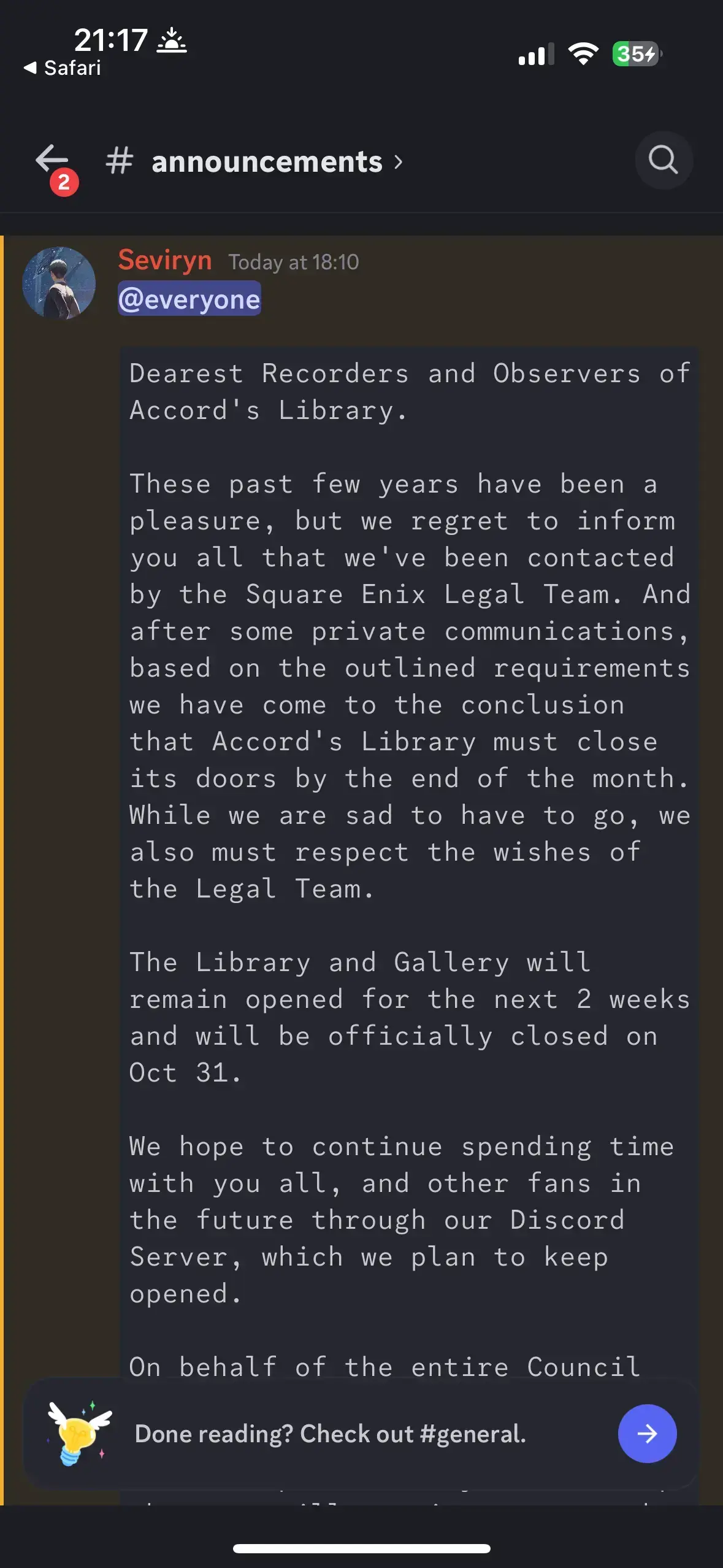
Today, in Accord's Library Discord, they announced that they received a Cease and Desist from Square-Enix, and on Oct 31, the Library and Gallery sections of the site will be closed and taken offline.
Announcement Text
Dearest Recorders and Observers of Accord's Library.
These past few years have been a pleasure, but we regret to inform you all that we've been contacted by the Square Enix Legal Team. And after some private communications, based on the outlined requirements we have come to the conclusion that Accord's Library must close its doors by the end of the month. While we are sad to have to go, we also must respect the wishes of the Legal Team.
The Library and Gallery will remain opened for the next 2 weeks and will be officially closed on Oct 31.
We hope to continue spending time with you all, and other fans in the future through our Discord Server, which we plan to keep opened.
On behalf of the entire Council for Accord's Library, we sincerely thank you for your support and friendship over the years. We hope that you will continue to use the discord, though we understand if this is where we part ways.
From the very bottom of our hearts, we will be forever grateful to everyone who's volunteered their time to help build Accord's Library into what it was. Thank you to all of our Transcribers, Translators, and most of all, all of you for sticking with us.
Take care of yourselves out there. Glory to Mankind.
- The Accord's Library Council
If anyone is skilled with backing up sites, any assistance would be appreciated. Even if it's just to point at the right tool for the job (been almost a decade since I've backed up part of a site).
Shoutout to !helloharu@lemmy.world making the original post.
- stallman-report.org The Stallman report
October 14th, 2024 Richard Stallman (aka “RMS”) is the founder of GNU and the Free Software Foundation and present-day voting member of the Free Software Foundation (FSF) board of directors and “Chief GNUisance” of the GNU project. He is responsible for innumerable contributions to the free software...
Good data to archive.
Hi everyone!
I've been using Create-Synchronicity for a few years, and it's been great for my needs. However, it hasn't been updated in a while, and I'm curious if there might be a more current alternative out there.
I'm looking for features like mirror, incremental, and two-way incremental backups, as well as the ability to schedule my backups. Opensource is a great plus.
There are plenty of options available, so I thought it would be a good idea to ask you all what you're using and what you would recommend.
Thanks a bunch for your help!
It's mostly old computer and gaming magazines at this time.
I tried to put emphasis on the personal nature of the question in the title. I'm not asking for myself or the average individual. I also mean ideal in the way where cost is still a factor. The iPhone 16 Pro has a 1TB model but it's around $500 more expensive than the 128GB version.
I imagine answers are going to vary significantly depending on an individuals approach like relying on cloud storage, SD cards, or a Magsafe NVMe drive for example.
I found 1TB (512GB on the phone and on the SD card) was ideal for me. I could keep the things I wanted for "just in case scenarios" like the files needed for the source ports of Diablo, Half Life, and Morrowind in case I want to play a game or some ebooks if I have time to read. I never needed to uninstall applications and shuffle things. I even had plenty of breathing room.
Another question I'd be interested in hearing people's answers to is what is the minimum storage capacity you would consider for a phone. I don't think I would buy a device with less than 256GB of potential storage. If it has an SD card slot that opens up the potential a significantly.
I have a bunch of old VHS tapes that I want to digitize. I have never digitized VHS tapes before. I picked up a generic HDMI capture card, and a generic composite to HDMI converter. Using both of those, I was planning on hooking a VCR up to a computer running OBS. Overall, I'm rather ignorant of the process. The main questions that I currently have are as follows:
- What are the best practices for reducing the risk of damaging the tapes?
- Are there any good steps to take to maximize video quality?
- Is a TBC required (can it be done in software after digitization)?
- Should I clean the VCR after every tape?
- Should I clean every tape before digitization?
- Should I have a separate VCR for the specific purpose of cleaning tapes?
Please let me know if you have any extra advice or recommendations at all beyond what I have mentioned. Any information at all is a big help.
Hey folks, I'm lucky enough to be in one of the few places on the internet that uses LTO.
I'm running LTO-8 tape. My current drive is kind of a dud, I'm interested in a new (to me) drive. Either internal in just an old desktop, or an external drive. I'm not afraid to shell out for it, but if I am I'm nervous to drop 2000 on just a random ebay seller. Anyone have any reputable sources? In the Seattle area if anyone knows a local one too.
Years ago I came across filecoin/sia decentralized data storage and I started trying them but then I stopped due to lack of time. Some days ago I've heard in a podcast about a kind of NAS that does kinda the same thing: it spreads chunks of data across other devices owned by other users.
Is there a service that does this but with your own hardware or, even better, something open source where you can have X GB as far as you share the same amount of space plus something extra?
It would be great for backup.
I'm entertaining the thought to write my backups onto tape storage. So my questiont to this community is: does someone know where (if any) to get cheap and simple (my requirements are "just writes & reads the data and is usable with a Linux machine") used tape drives?
Thanks for any hints.

[The guide isn't mine and I'm not affiliated with it, I'm just sharing a mind-blown moment for me.]
Over the years, I have gathered many notebooks that admittedly not all contain very important information and take up a lot of space (possibly a cubic meter or more). But being kind of a (data)hoarder, I dont want to just throw them away. It's work that took years.
My solution: scanning them. My phone has a built-in camera scanner that does a suprisingly good job (it helps that the camera is kinda good too), so I have scanned thousands of pages so far. But the process is slow and takes a lot of manual labor (flipping pages, aligning pages, retaking bad photos, creating pds etc.). A typical notebook (~120pages) may take me 15minutes or more.
So I thought that maybe I could speed up the process (partially at least) by either buying a scanner or paying someone to scan them (I don't have a proper scanner, yet). Removing the pages without damaging them is a challenge though. That's where the guide in the link comes in: it turns out it's very easy to remove the spiral spring from the notebooks! I was gonna pull the pages until I found that guide. I suppose it's also very easy to remove the staples from staple-bound notebooks too. I might just have "won" many hours of my life with this idea.
The video in the guide that helped me:
https://www.youtube.com/watch?v=lfMUVpwLZGM
(For the record, my xiaomi 10 phone can scan items by creating ~20MP images which translates to typical-to-high resolutions if I scan A4 or A5 pages. Fortunately, many scanners can reach that quality. I just need them not to apply any weird effects or compression to the scanned document.)
Hi everyone,
I'm looking for a more efficient way to save and archive Lemmy comments and posts on my Android phone. Currently, when I come across a comment I want to keep for future reference, I manually copy the text and link, then paste it into a note in my Obsidian vault. If there's an image or other media in the original post, I save and include that as well.
However, this process feels a bit cumbersome. Ideally, I’d like a way to quickly save or share a comment or post URL and automatically archive the top 20 or so comment chains, along with the original post, including any images, videos, or articles.
Has anyone found a streamlined method for doing this? I often find that by the time I return to check the responses or review the content, the post or article has disappeared. Any tips or tools that could help simplify this process would be greatly appreciated!
Thanks in advance for your suggestions!
cross-posted from: https://lemmy.dbzer0.com/post/26278528
> I'm running my media server with a 36tb raid5 array with 3 disks, so I do have some resilience to drives failing. But currently can only afford to loose a single drive at a time, which got me thinking about backups. Normally I'd just do a backup to my NAS, but that quickly gets ridiculous for me with the size of my library, which is significantly larger than my NAS storage of only a few tb. And buying cloud storage is much too expensive for my liking with these amounts of storage. > > Do you backup only the most valuable parts of your library?
I'm celebrating my datahoarding problem.
cross-posted from: https://sh.itjust.works/post/23677247
> Ensh*ttification > > https://m.ai6yr.org/@ai6yr/112956803111115013
- archive.org GameFAQs TXT August 2024 : thingsiplay : Free Download, Borrow, and Streaming : Internet Archive
https://archive.org/details/gamefaqs_txtby thingsiplay (Tuncay D.)2024-08-07GameFAQs at https://gamefaqs.gamespot.com hosts user created faqs anddocuments....

cross-posted from: https://beehaw.org/post/15404535
Data: https://archive.org/details/gamefaqs_txt
> Mirror upload for faster download, 1 Mbit (expires in 30 days): https://ufile.io/f/r0tmt > > GameFAQs at https://gamefaqs.gamespot.com hosts user created faqs and > documents. Unfortunately they are baked into the HTML webpage and cannot be > downloaded on their own. I have scraped lot of pages and extracted those > documents as regular TXT files. Because of the sheer amount of data, I only > focused on a few systems. > > In 2020, a Reddit user named "prograc" archived faqs for all systems at > https://archive.org/details/Gamespot_Gamefaqs_TXTs . So most of it is already > preserved. I have a different approach of organizing the files and folders. > Here a few notes about my attempt: > > * only 17 selected systems are included, so it's incomplete > * folder names of systems have their long name instead short, i.e. Playstation > instead ps > * similarly game titles have their full name with spaces, plus a starting "The" > is moved to the end of the name for sorting reasons, such as "King of > Fighters 98, The" > * in addition to the document id, the filename also contain category (such as > "Guide and Walkthrough"), the system name in short "(GB)" and the authors > name, such as "Guide and Walkthrough (SNES) by BSebby_6792.txt" > * the faq documents contain an additional header taken from the HTML website, > including a version number, the last update and the previously explained > filename, plus a webadress to the original publication > * HTML documents are also included here with a very poor and simple conversion, > but only the first page, so multi page HTML faqs are still incomplete > * no zip archives or images included, note: the 2020 archive from "prograc" > contains false renamed .txt files, which are in reality .zip and other files > mistakenly included, in my archive those files are correctly excluded, such > as
nes/519689-metroid/faqs/519689-metroid-faqs-3058.txt> * I included the same collection in an alternative arrangement, where games are > listed without folder names for the system, this has the side effect of > removing any duplicates (by system: 67.277 files vs by title: 55.694 files), > because the same document is linked on many systems and therefore downloaded > multiple times Hey guys, so it seems that Linkwarden isn't as good as I was hoping, since some websites will throw up a cookie popup or some other screen that basically prevents the capture.
Firefox Screenshot seems to work well, but it saves a PNG, which isn't really text searchable.
FF's "save page as..." feature seems to break things when viewing them back.
Save to PDF is another option, and that seems to be decent.
I'm not looking to copy entire websites, but I like to save web pages for later reference (i.e. instructions/specs).
I use Synology Note Station, but they don't have a web clipper for Firefox...
I'm fine with using a folder structure to store files, despite not being totally ideal when compared to Linkwarden.
Does anyone have any other suggestions that perhaps I've missed? Nothing too complicated... ideally, as simple as a button click would be great.
- www.backblaze.com Backblaze Drive Stats for Q2 2024
Read the Q2 2024 Drive Stats Report, with the latest on annualized failure rates and a look into measuring drive consistency over time.

YouTube is cracking down Adblocker and they may never work in a year or so.
I don't watch YouTube that much and most of the time I watch the same thing. So I am thinking of mirroring the videos I watch to other platforms. But I don't know which. I was just thinking of ok.ru. I don't know if they respond to DMCA requests.
Did anyone do something similar?
Running GParted gives me an error that says
> fsyncing/closing dev/sdb: input/output error
Using Gnome Disk Utility under the assessment section it says
> Disk is OK, one bad sector
Clicking to format it to EXT4 I'm getting a message that says
> Error formatting volume
> Error wiping device: Failed to probe the device 'dev/SDB' (udisks-error-quark, 0)
Running sudo smartctl -a /dev/SDB I get a few messages that all say
> ... SCSI error badly formed scsi parameters
---
In terms of the physical side I've swapped out the SATA data and power cable with the same results.
---
Any suggestions?
Amazon has a decent return policy so I'm not incredibly concerned but if I can avoid that hassle it would nice.
a few days ago i saw a post on the reddit datahoarder community asking how to backup keys and other small files for a long time. it reminded me of a script i made some time ago to save my otp secrets in case of loss of device or a reenactment of the raivo otp incident, so i decided to make it public on github, hope someone here finds it useful
the density is not great, about 1kB per A4 page, but it can recover from losing up to half of the printed surface and, if stored properly, paper should last very long
Basically title!
I want to run it through my NAS to free up some space.
Tha ks in advance.
I read something about once-reliable sites that would tell you the best [tech thing] now not giving legit reviews, being paid to say good things about certain companies, and I do not remember where I read that or which sites, so I figured I'd bypass the issue and ask people here. I'm pretty new to anything near the level of complexity and technical details that I see on datahoarder communities. I know about the 321 backup rule and that's it. This is me trying to find something to hold copy 3 of my data.
i want to buy a few hard drives for backups.
What is the most reliable option for longetivity? i was looking at the wd ae, which they claim is fit for this purpose, but knowing nothing about hard drives, I wouldnt know if it was a marketing claim..
cross-posted from: https://lemmy.world/post/17689141
> I'll just save them in this folder so that I can totally come back later and read them.
I was considering making a 30+ TB NAS to simplify and streamline my current setup but because it's a relatively low priority for me I am wondering is it worth it to hold off for a year or two?
I am unsure if prices have more or less plateaued and the difference won't be all that substantial. Maybe I should just wait for Black Friday.
For context it seems like two 16TB HDD would cost about $320 currently.
---
Here's some related links:
Are they worth considering or only worth it at certain price points?
cross-posted from: https://slrpnk.net/post/10273849
> Vimms Lair is getting removal notices from Nintendo etc. We need someone to help make a rom pack archive can you help? > > Vimms lair is starting to remove many roms that are being requested to be removed by Nintendo etc. soon many original roms, hacks, and translations will be lost forever. Can any of you help make archive torrents of roms from vimms lair and cdromance? They have hacks and translations that dont exist elsewhere and will probably be removed soon with ios emulation and retro handhelds bringing so much attention to roms and these sites
- gitlab.com starshiners / PGSub · GitLab
Large Postgres database of collected subtitles with companion apps to access them.

I've been working on this subtitle archive project for some time. It is a Postgres database along with a CLI and API application allowing you to easily extract the subs you want. It is primarily intended for encoders or people with large libraries, but anyone can use it!
PGSub is composed from three dumps:
- opensubtitles.org.Actually.Open.Edition.2022.07.25
- Subscene V2 (prior to shutdown)
- Gnome's Hut of Subs (as of 2024-04)
As such, it is a good resource for films and series up to around 2022.
Some stats (copied from README):
- Out of 9,503,730 files originally obtained from dumps, 9,500,355 (99.96%) were inserted into the database.
- Out of the 9,500,355 inserted, 8,389,369 (88.31%) are matched with a film or series.
- There are 154,737 unique films or series represented, though note the lines get a bit hazy when considering TV movies, specials, and so forth. 133,780 are films, 20,957 are series.
- 93 languages are represented, with a special '00' language indicating a .mks file with multiple languages present.
- 55% of matched items have a FPS value present.
Once imported, the recommended way to access it is via the CLI application. The CLI and API can be compiled on Windows and Linux (and maybe Mac), and there also pre-built binaries available.
The database dump is distributed via torrent (if it doesn't work for you, let me know), which you can find in the repo. It is ~243 GiB compressed, and uses a little under 300 GiB of table space once imported.
For a limited time I will devote some resources to bug-fixing the applications, or perhaps adding some small QoL improvements. But, of course, you can always fork them or make or own if they don't suit you.
- • 92%www.theregister.com Blame the SSD price hike on enterprise demand for AI servers
Samsung, SK, Kioxia and others make bank, booking double digit bounces in Q1 revenue

{kind=link}